全系列时间线演进
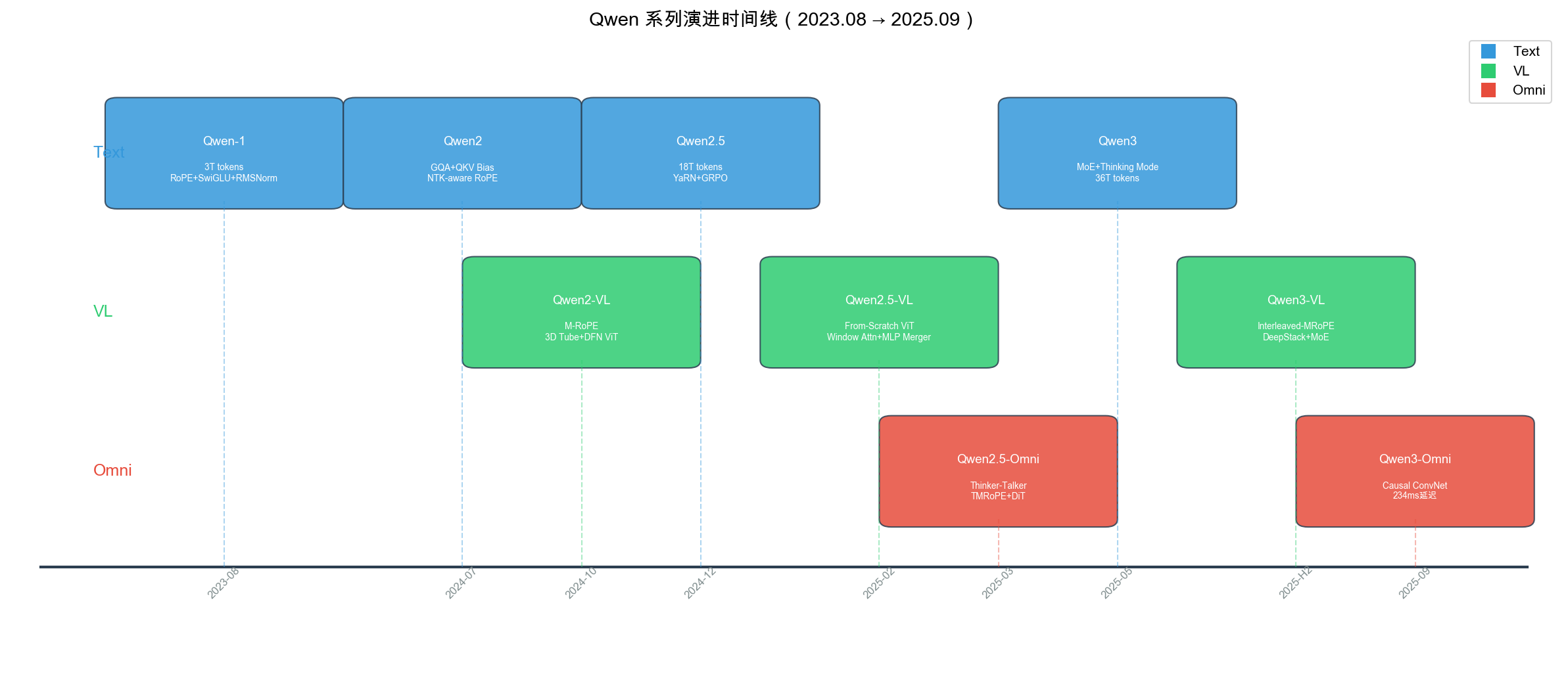
横轴发布时间,纵轴分 Text / VL / Omni 三条产品线
六大架构演进脉络总览
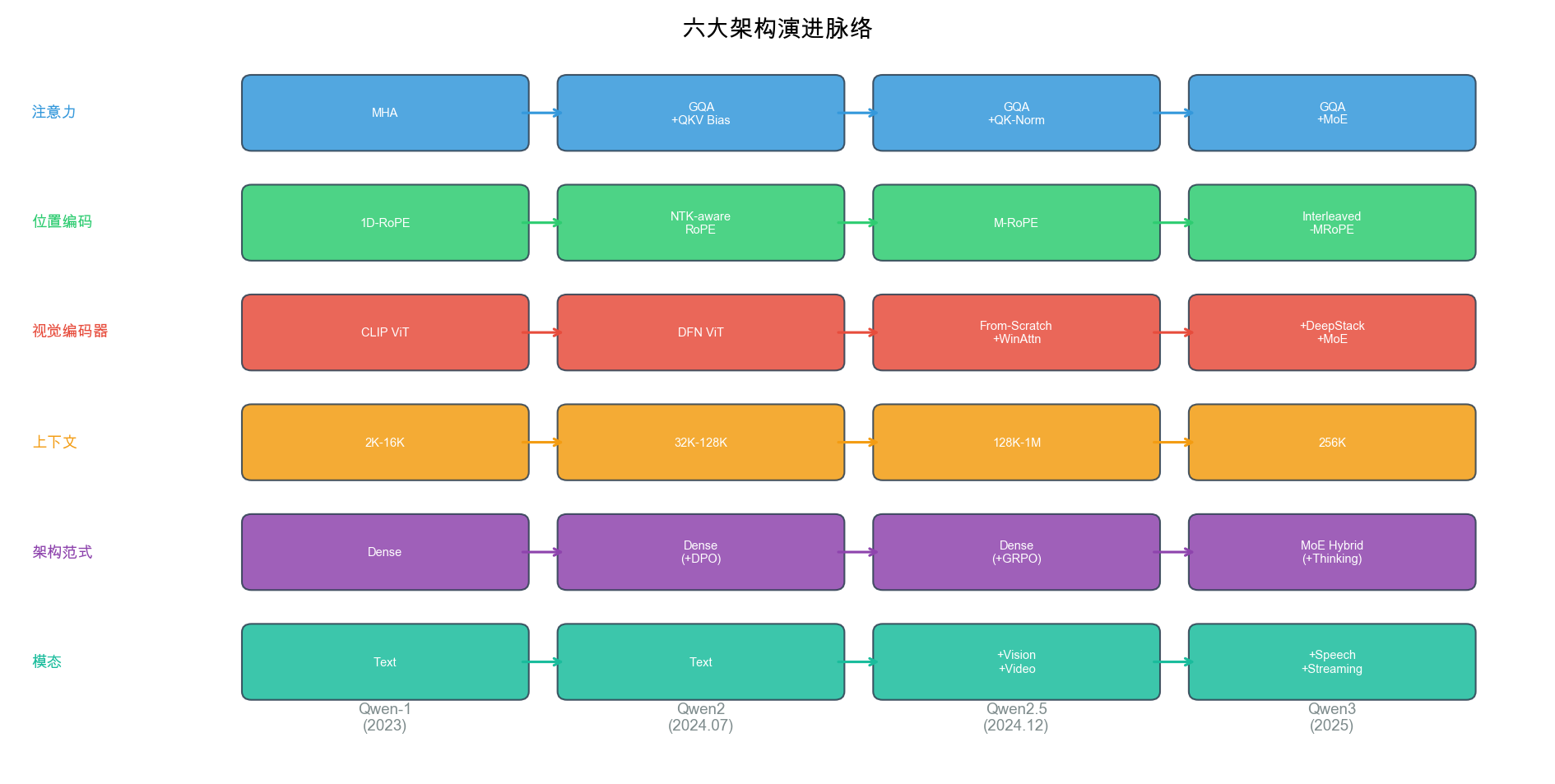
注意力机制 / 位置编码 / 视觉编码器 / 上下文长度 / 架构范式 / 模态支持
初代 Qwen:LLaMA 架构的继承与优化
继承 LLaMA 的四大核心组件
| 组件 | 技术选型 | 设计原理 |
|---|---|---|
| 归一化 | RMSNorm (pre-norm) | 移除均值项,仅用 RMS 缩放,快 7-10% |
| 激活函数 | SwiGLU | Swish 门控 + 双投影,避免神经元死亡 |
| 位置编码 | RoPE | 旋转矩阵编码相对位置,支持外推 |
| 注意力 | Standard MHA | 标准多头注意力,全参数 |
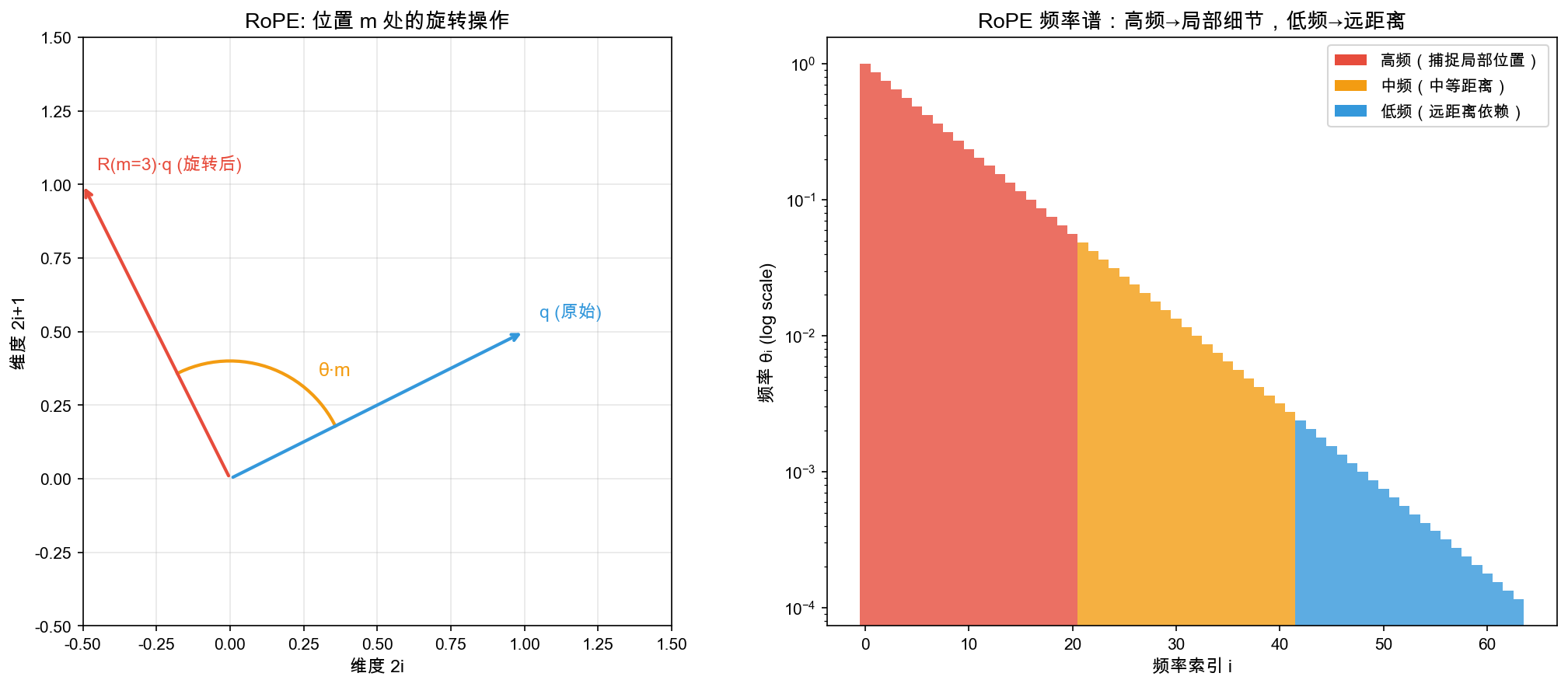
RoPE 旋转位置编码:位置 m 对应旋转角度 θ·m
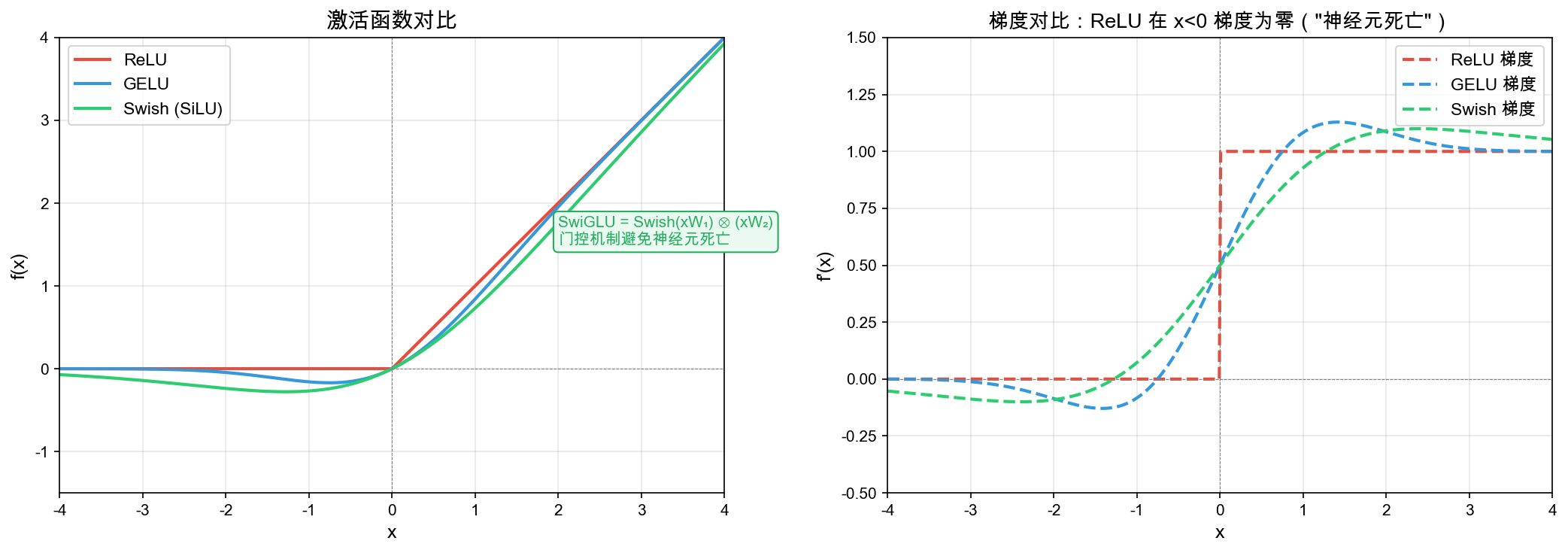
SwiGLU vs ReLU/GELU 激活函数对比
Qwen-1 的三项独特创新
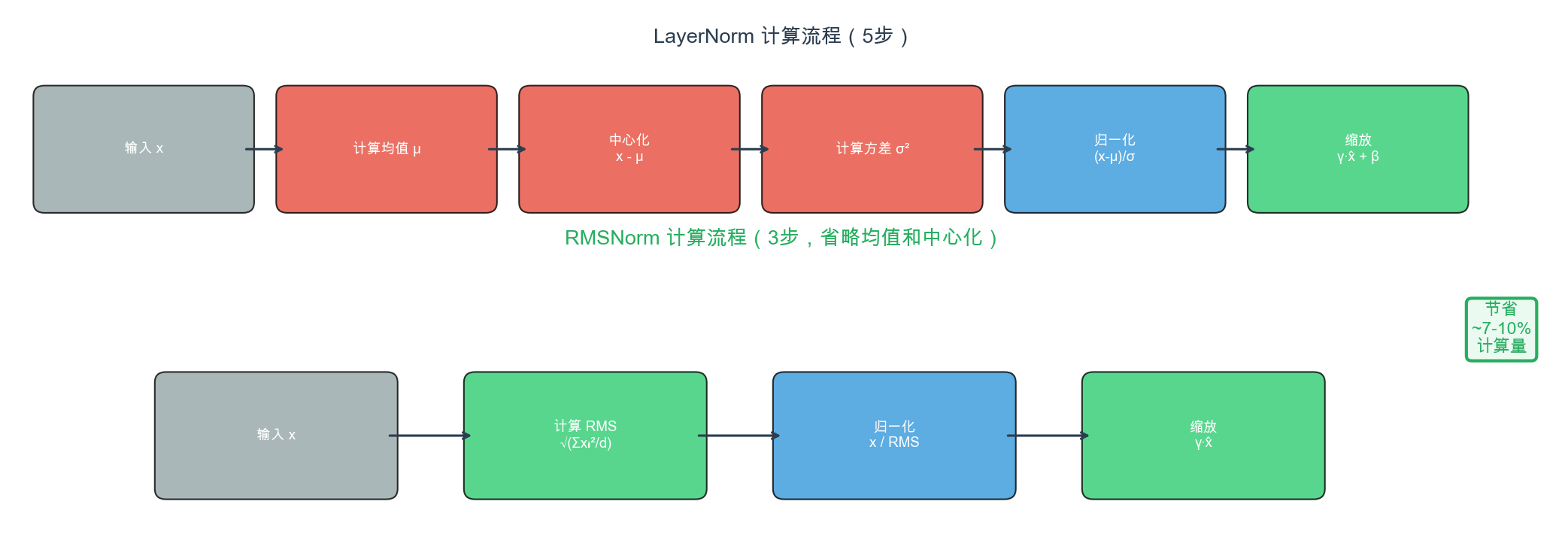
LayerNorm(5 步) vs RMSNorm(3 步)计算流程
多语言优化,中文分词效率提升 ~2x
提供与输入无关的「默认」注意力方向
输入输出嵌入独立,更好的输出分布
Qwen2:架构独立创新的起点
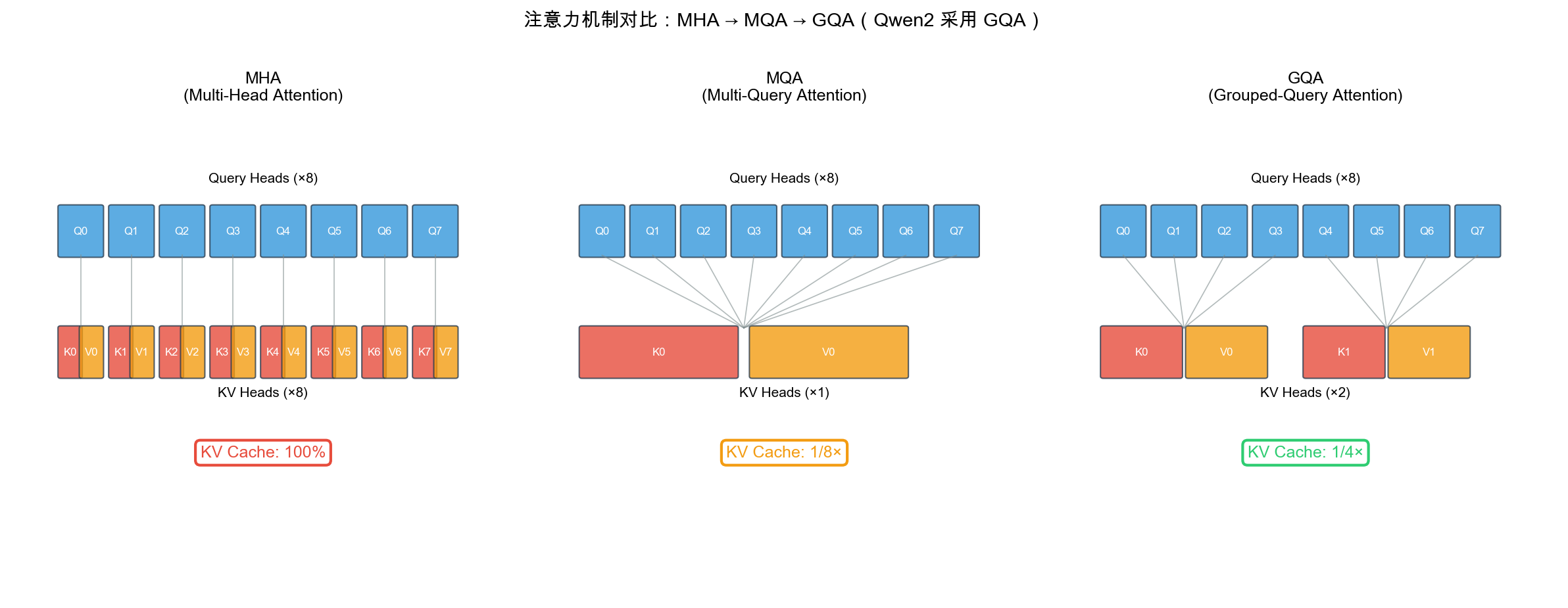
MHA vs MQA vs GQA:Q/KV 头数分配
创新 1:全尺寸 GQA(Grouped Query Attention)
- 激进策略:所有尺寸(含 0.5B)均用 GQA,LLaMA 仅 70B 使用
- KV Cache 节省 8x:128K 上下文从 4GB → 512MB
- 核心判断:长上下文时代,推理效率 > 训练时 0.3 MMLU 损失
- 用 7T 高质量数据补偿 GQA 性能损失
创新 2:QK-Norm 替代 QKV Bias
- 长序列下 QKV Bias 导致 attention logits 累积爆炸
- QK-Norm 将 Q/K 归一化到单位范数,动态范围可控
- 比 QKV Bias 提升 0.5-1 MMLU
Qwen2 创新 3:NTK-aware RoPE 频率分区
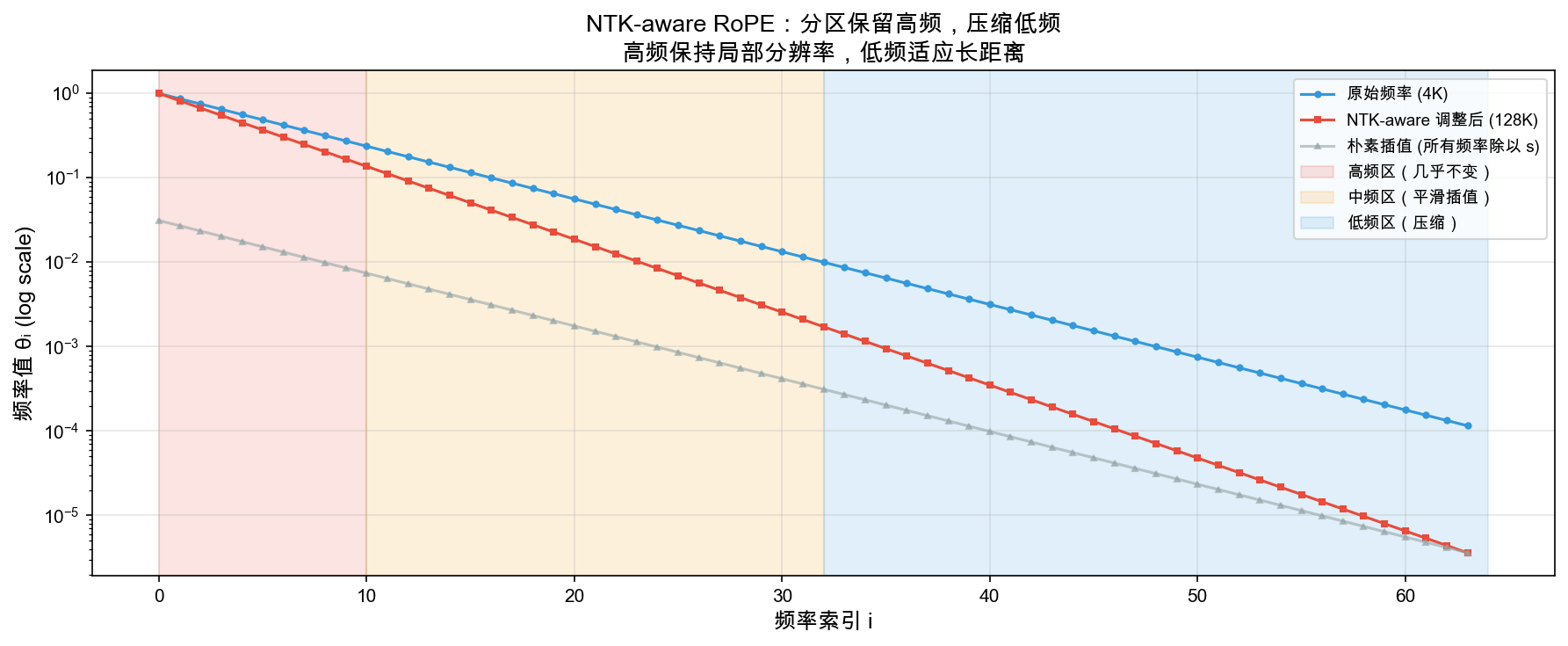
NTK-aware RoPE 三区间频率处理
NTK-aware 分频策略
- 高频维度(i 小):保持原频率,保留局部细节分辨率
- 中频维度:平滑渐进插值,过渡区域
- 低频维度(i 大):按比例压缩,适应更长序列
比喻:只降低贝斯音调以适应更大厅堂,小提琴高音保持不变 — 长距离信号频率降低以覆盖更长范围
Qwen2.5:数据规模与长上下文突破
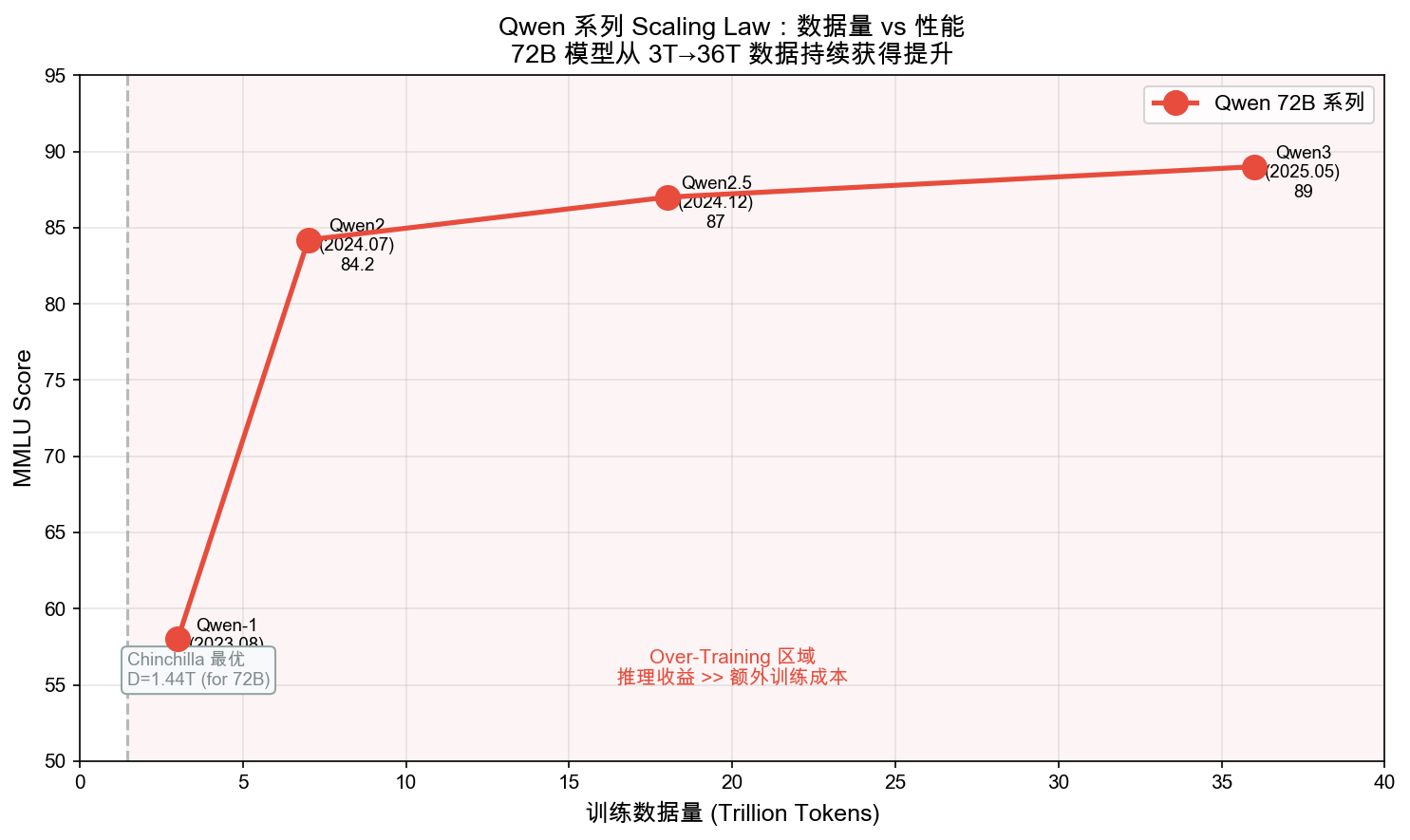
72B 模型 3T → 36T 数据的 MMLU 提升曲线
创新 1:18T 数据(6x Qwen-1)
- Over-Training:12.5x Chinchilla 最优 — 推理成本远大于训练成本
- 合成数据 ~20%:用 Qwen2-72B 生成推理样本,引入新信息维度
- OCR 提取:Qwen2.5-VL 从 PDF 提取结构化文本
Qwen2.5 创新 2-3:YaRN 与 GRPO
创新 2:YaRN — 128K → 1M 上下文
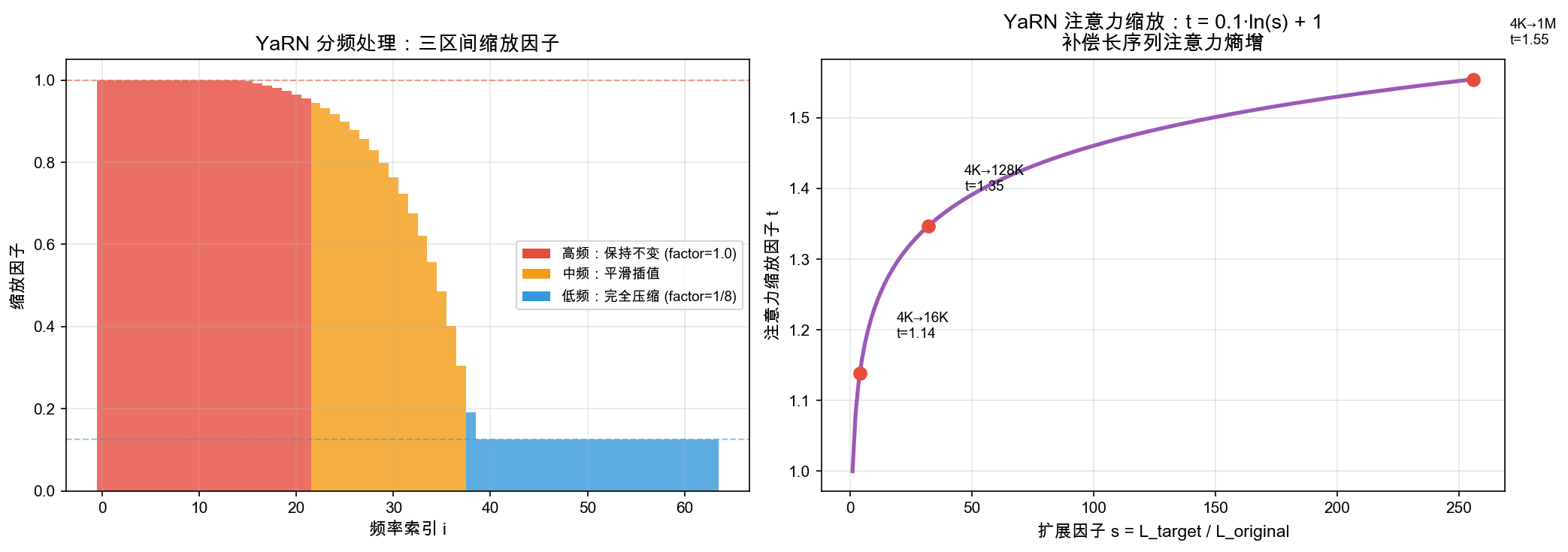
- 分频处理:高频不变 / 中频渐进 / 低频压缩
- 注意力缩放:t = 0.1·ln(s) + 1,抵消注意力稀释
- 渐进式扩展:4K → 32K → 128K → 1M,每阶段用不同训练数据
- Needle-in-Haystack 1M 准确率 98.5%
创新 3:GRPO 无 Critic 强化学习
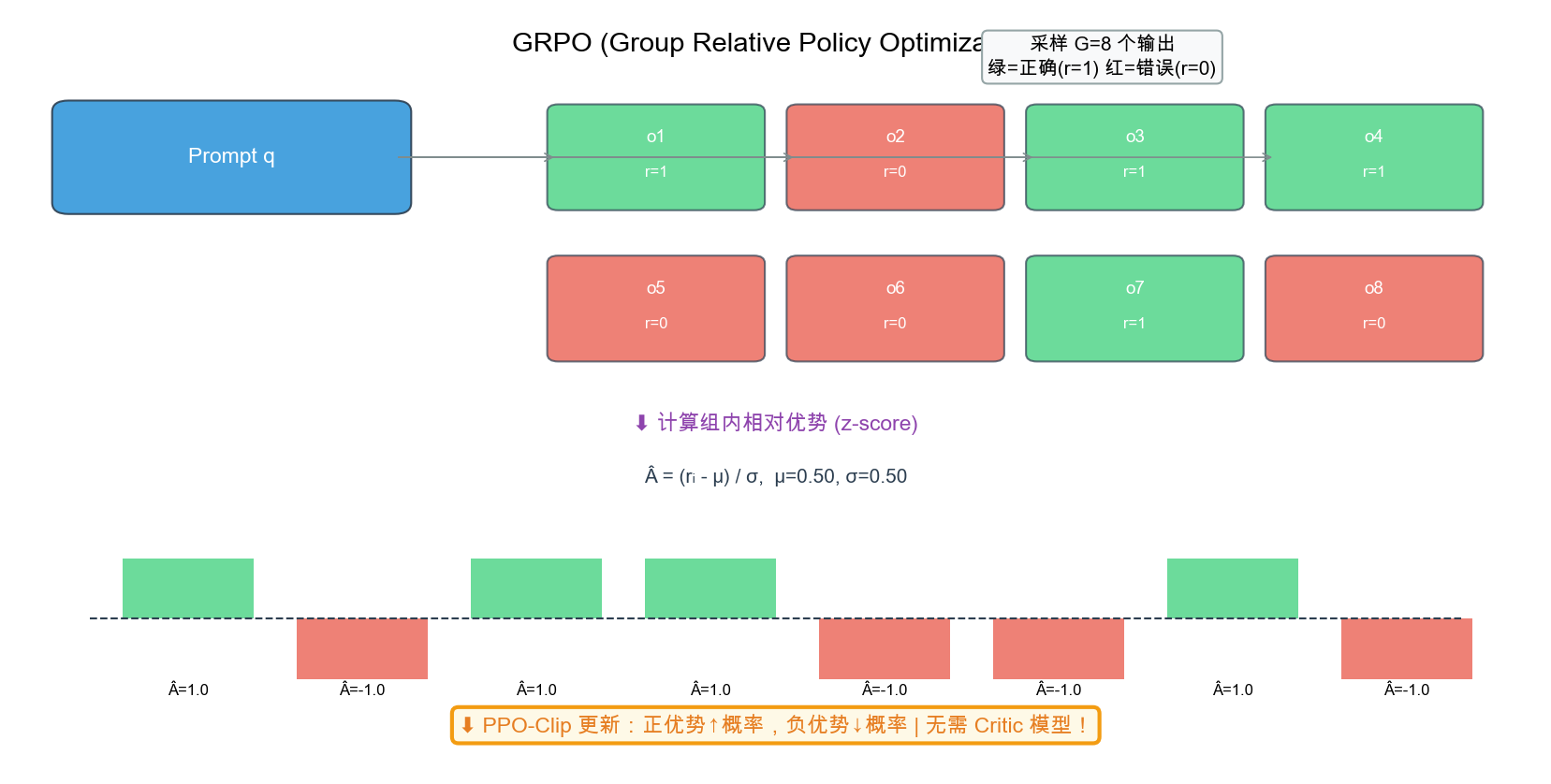
- 核心思想:每题采样 G=8 个输出,组内 z-score 做优势估计
- 无需 Critic:显存节省 ~30%(对 72B 意味着省 72B 参数)
- 三阶段 RL:DPO(对齐)→ GRPO(推理)→ PPO(长文本)
- MATH 达 85 分,超越 GPT-4o(76.6)
Qwen3:混合 MoE 与动态推理革命
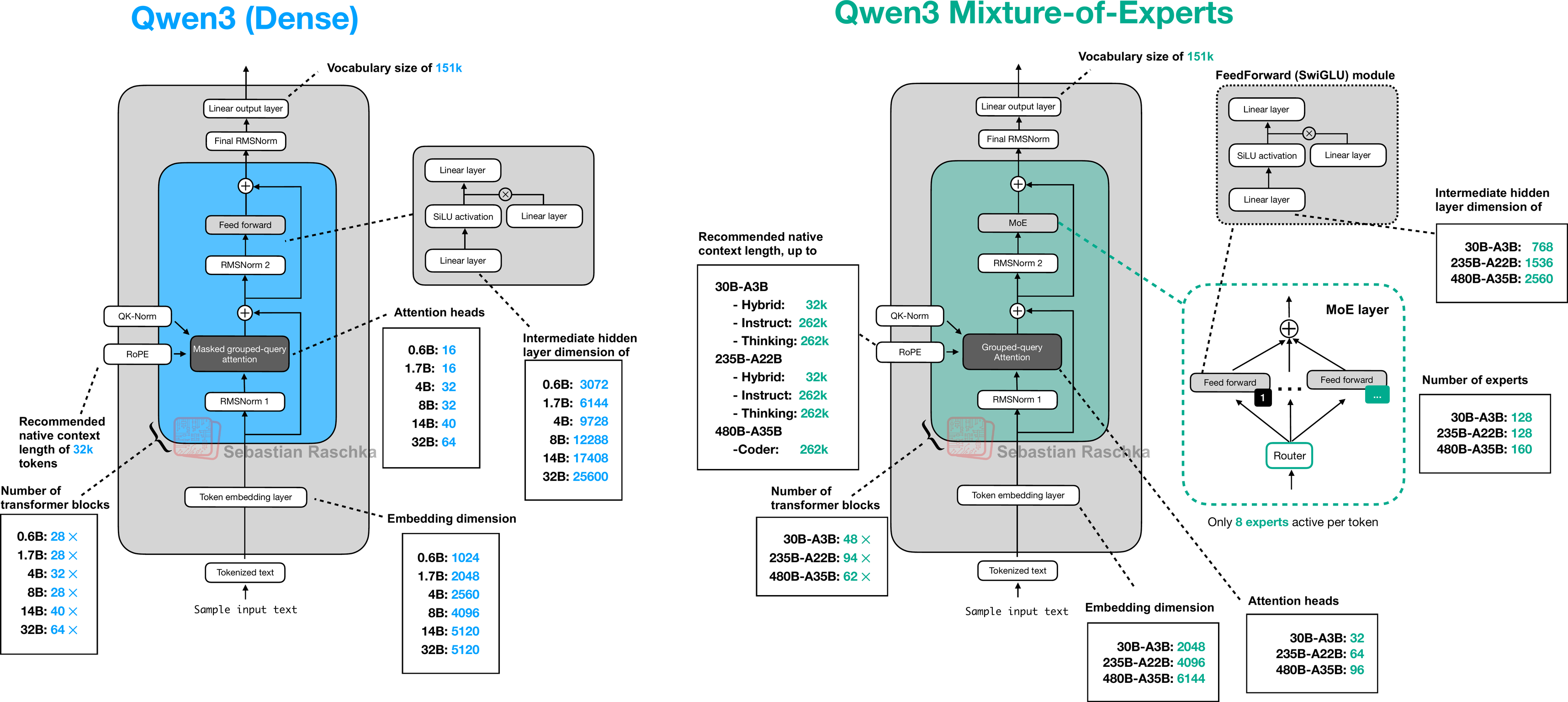
Qwen3 Technical Report: MoE + Thinking 架构
| 维度 | Qwen2.5 | Qwen3 |
|---|---|---|
| 训练数据 | 18T / 29 语言 | 36T / 119 语言 |
| 架构 | 纯 Dense | Dense + MoE |
| 推理模式 | 单一 | Thinking + Non-Thinking |
| 旗舰 | 72B Dense | 235B-A22B MoE |
| MMLU | ~87 | ~89 |
MoE 路由:128 专家 Top-8 + 共享专家
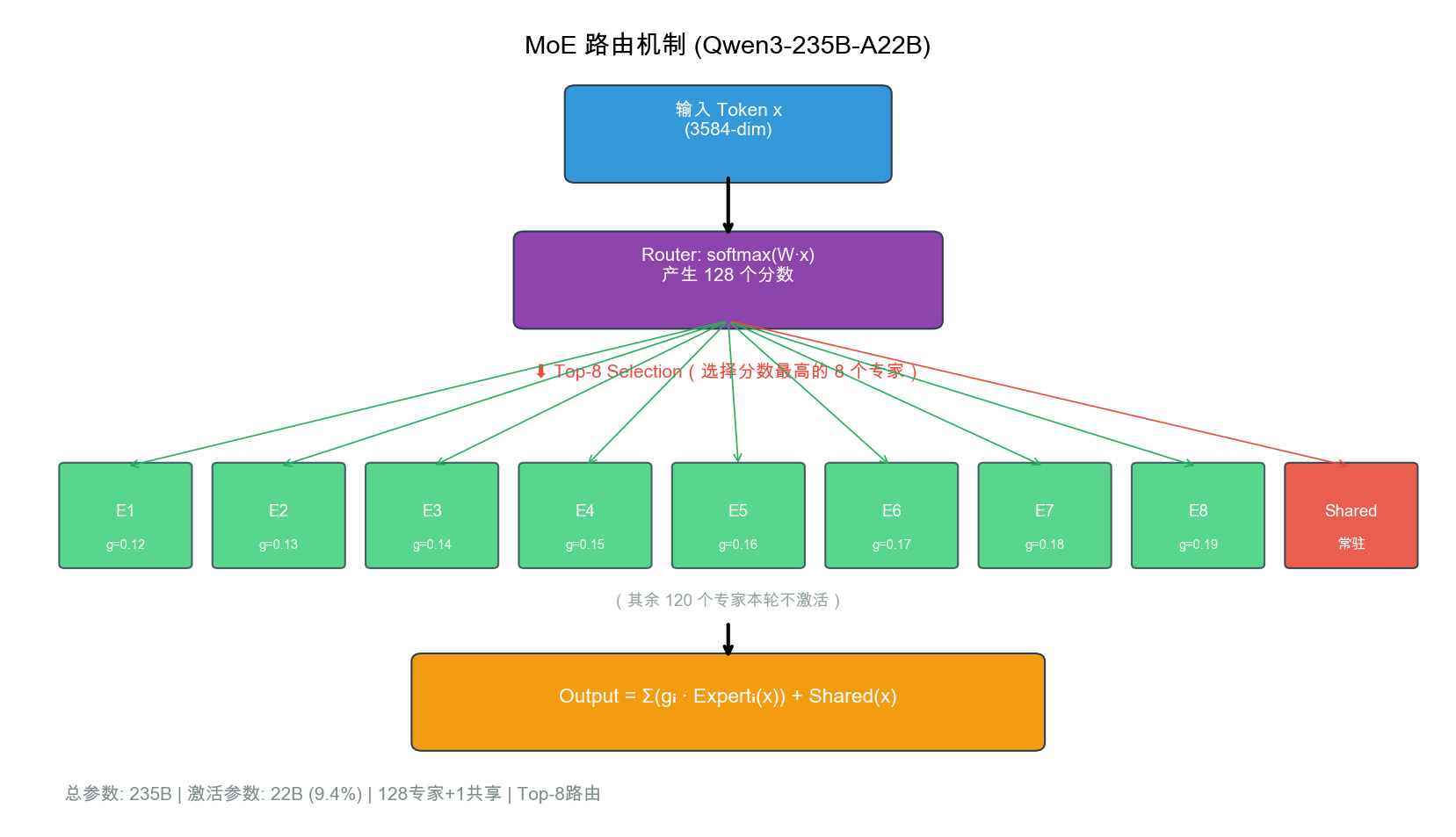
Token → Router → Top-8 加权 + 共享专家
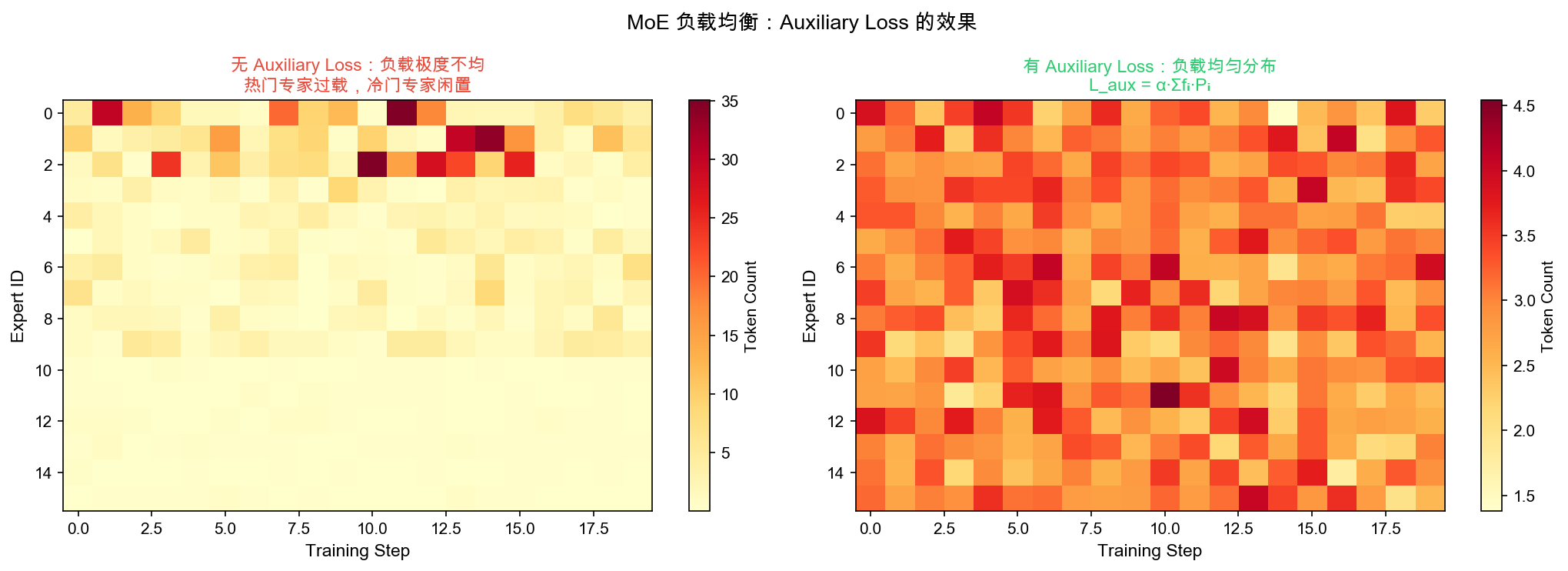
Auxiliary Loss 平衡专家负载分布
| 模型 | 总参 | 激活 | MMLU/激活参数 |
|---|---|---|---|
| Qwen3-235B | 235B | 22B | 4.05(最优) |
| DeepSeek-V3 | 671B | 37B | 2.38 |
| LLaMA3-405B | 405B | 405B | 0.21 |
负载均衡三策略
- 辅助损失(λ=0.01):惩罚高负载 × 高概率的专家
- 容量因子(CF=1.25):限制单专家最大负载
- 共享专家(1 个):保底能力 + 吸收溢出 token
统一 Thinking Mode:动态推理深度控制
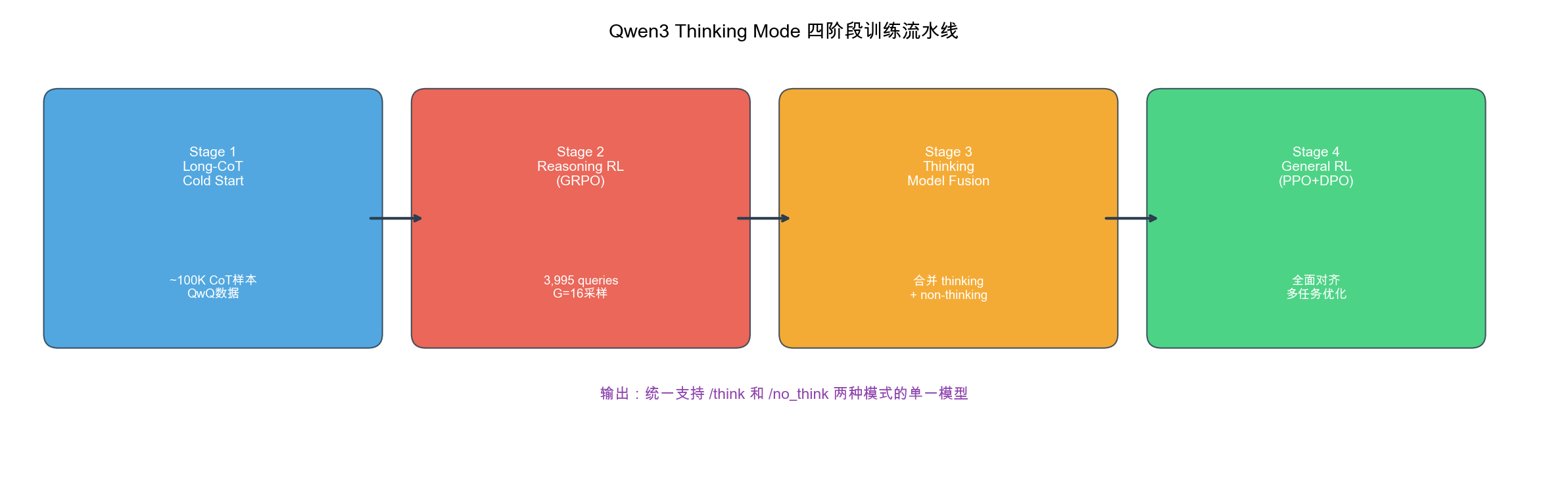
四阶段训练:CoT 冷启动 → GRPO → Fusion → General RL
四阶段训练流程
- Stage 1:Long-CoT 冷启动(~100K 精选样本)— 教模型「先想后答」
- Stage 2:GRPO 推理 RL(仅 3,995 query)— 质量极高,G=16 采样
- Stage 3:Thinking Fusion — 统一 /think 与 /no_think(1:2 混合)
- Stage 4:General RL — PPO + DPO 全面对齐
强到弱蒸馏:90% 训练成本节省
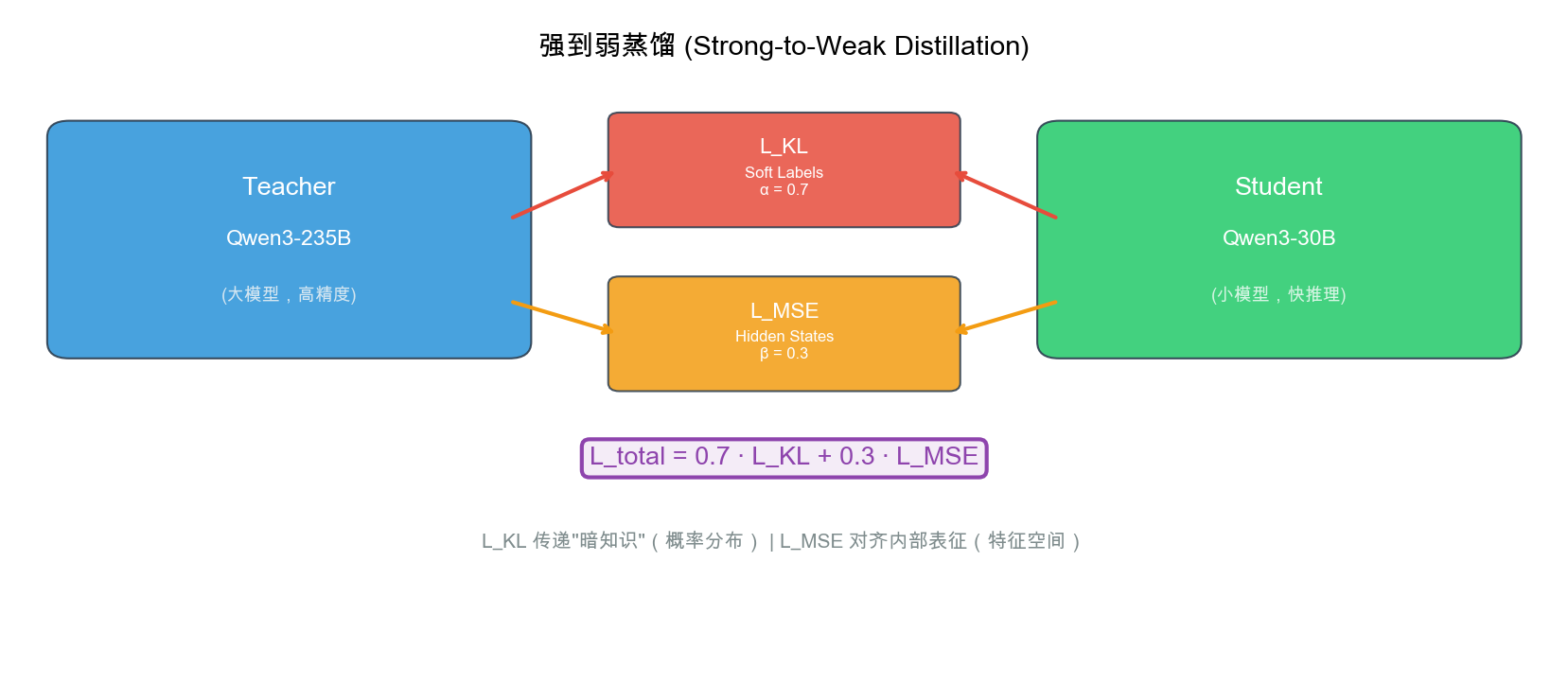
LKL(暗知识 α=0.7)+ LMSE(特征对齐 β=0.3)
暗知识(Dark Knowledge)
- 教师输出 [0.02, 0.15, 0.70, 0.10, 0.03] — 包含错误选项间的相对排序
- 学生不仅学「C 最好」,还学「B 比 D 好,A 和 E 都差」
蒸馏路线
- 235B-A22B → 30B-A3B(MoE 到 MoE)
- 32B → 0.6B / 1.7B / 4B(Dense 到 Dense)
- 成本:30,000 GPU hours → 3,000 GPU hours
- 关键:小模型也获得 Thinking 能力(蒸馏传递推理模式)
Qwen-VL:Cross-Attention Resampler 范式
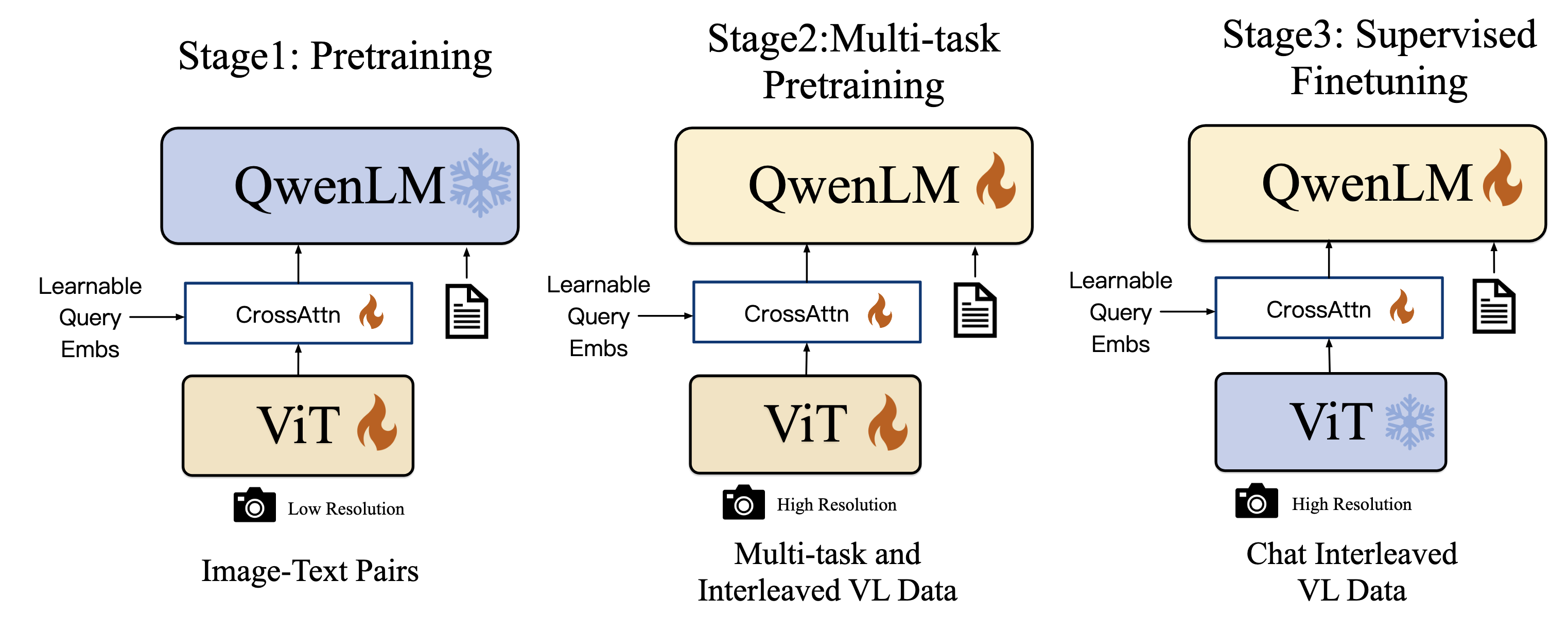
ViT-bigG → Cross-Attention → 固定 256 token → Qwen-7B
三组件设计
- ViT-bigG(1.9B):OpenCLIP 预训练权重,视觉特征提取
- VL Adapter:256 可学习 query + 2D 绝对位置编码 — 核心创新
- Qwen-7B:语言理解与生成
三阶段训练
- Stage 1:冻结 LLM,训练 ViT + Adapter(224² 分辨率)
- Stage 2:全模型训练 7 类任务(448²,OCR 数据 24.8M 占比最大)
- Stage 3:冻结 ViT,SFT 35 万指令
Qwen2-VL 创新 1:M-RoPE 多模态位置编码

M-RoPE:head 维度三等分,编码 t/h/w 三维
M-RoPE 三维分解
| Token 类型 | t(时间) | h(高度) | w(宽度) |
|---|---|---|---|
| 文本 | pos | pos | pos |
| 图像 (r, c) | 固定常量 | 行索引 r | 列索引 c |
| 视频帧 f (r, c) | 帧序号 f | 行索引 r | 列索引 c |
比喻:GPS 坐标系 — 经度/纬度/海拔唯一确定每个点;文本 token 三坐标同步递增时退化为 1D-RoPE
Qwen2-VL:动态分辨率 + 3D Tube 视频压缩
创新 2:朴素动态分辨率
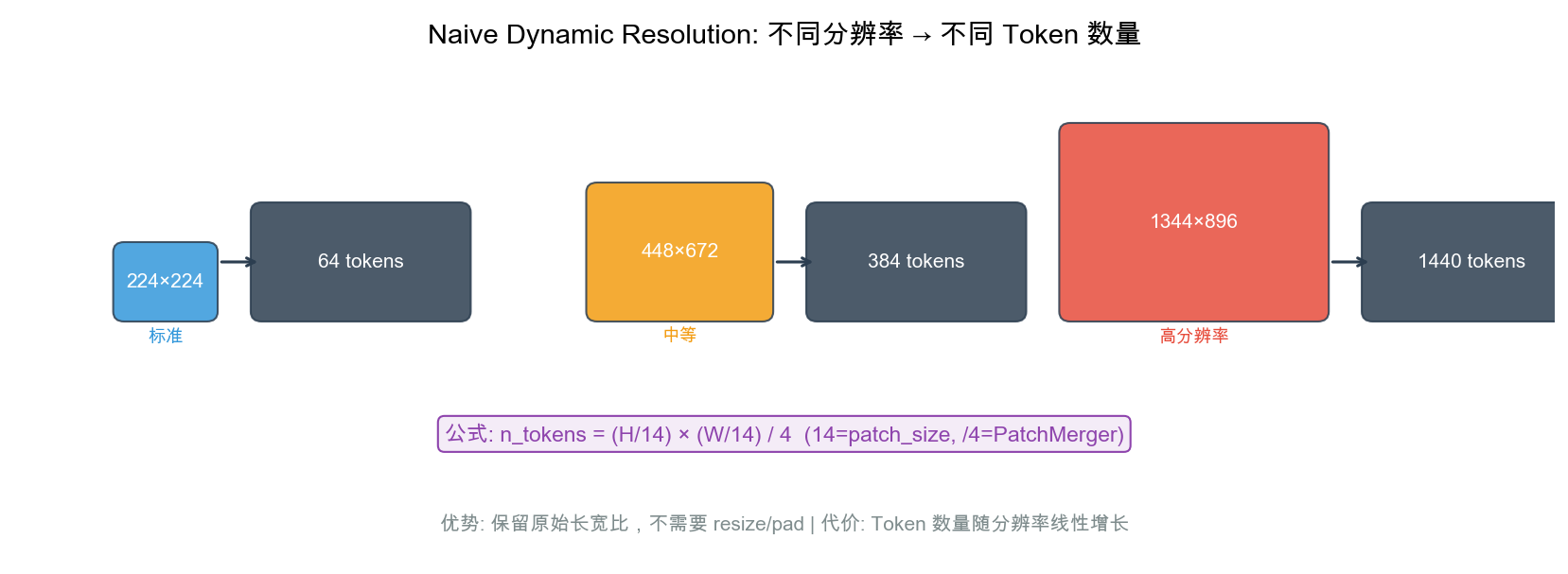
- 任意尺寸输入,不 resize / 不 pad
- Token 数 = (H/28) × (W/28)(含 PatchMerger 4:1 压缩)
- 模拟人类视觉选择性注意力:需要细看的分配更多 token
创新 3:3D Tube 时空压缩
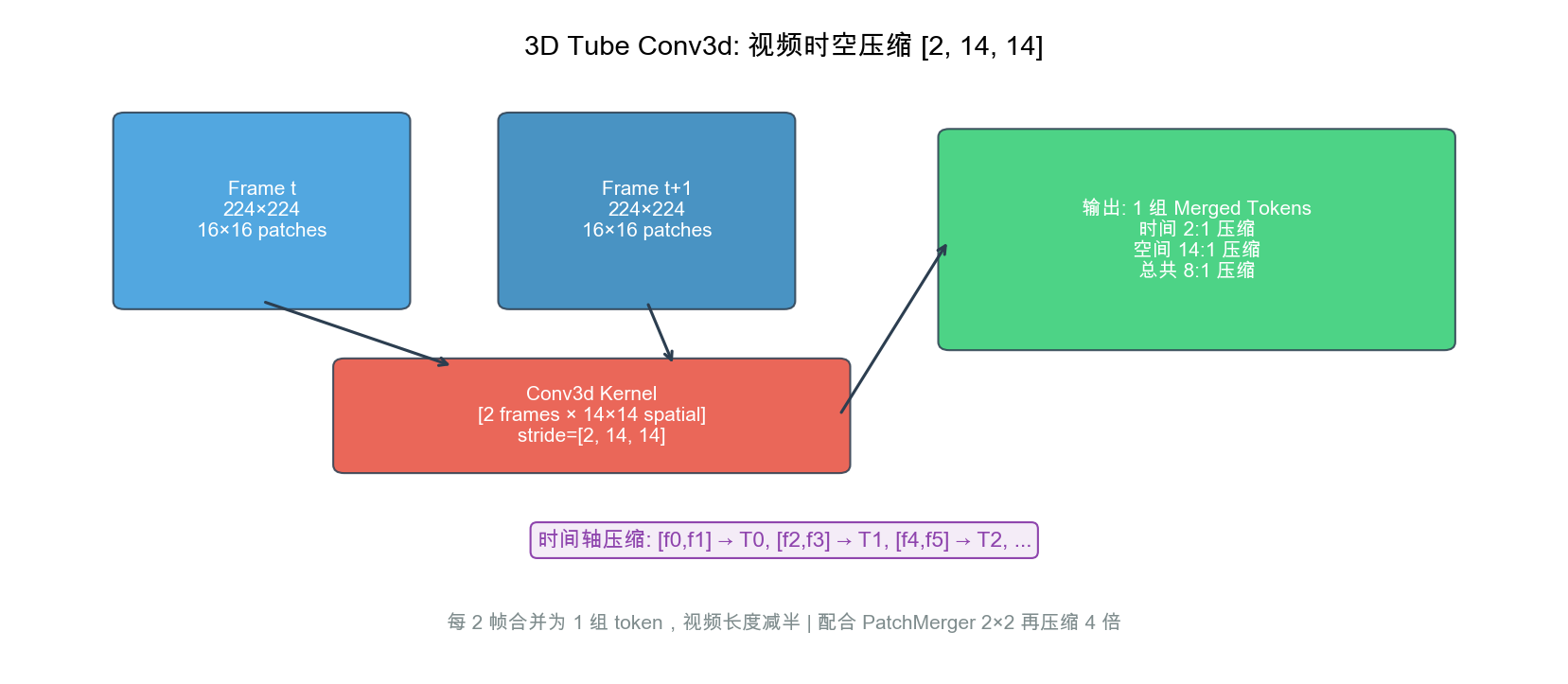
- Conv3d [2, 14, 14]:相邻两帧同一位置压缩为 1 token
- 时间 2x 压缩 + PatchMerger 4:1 空间压缩 = 总 8:1
- 视频相邻帧 99% 内容相同 — 利用时间冗余
- 静态图像:复制为 2 帧,统一走 3D Tube 路径
Qwen2.5-VL 创新 1:从零训练 ViT + Window Attention
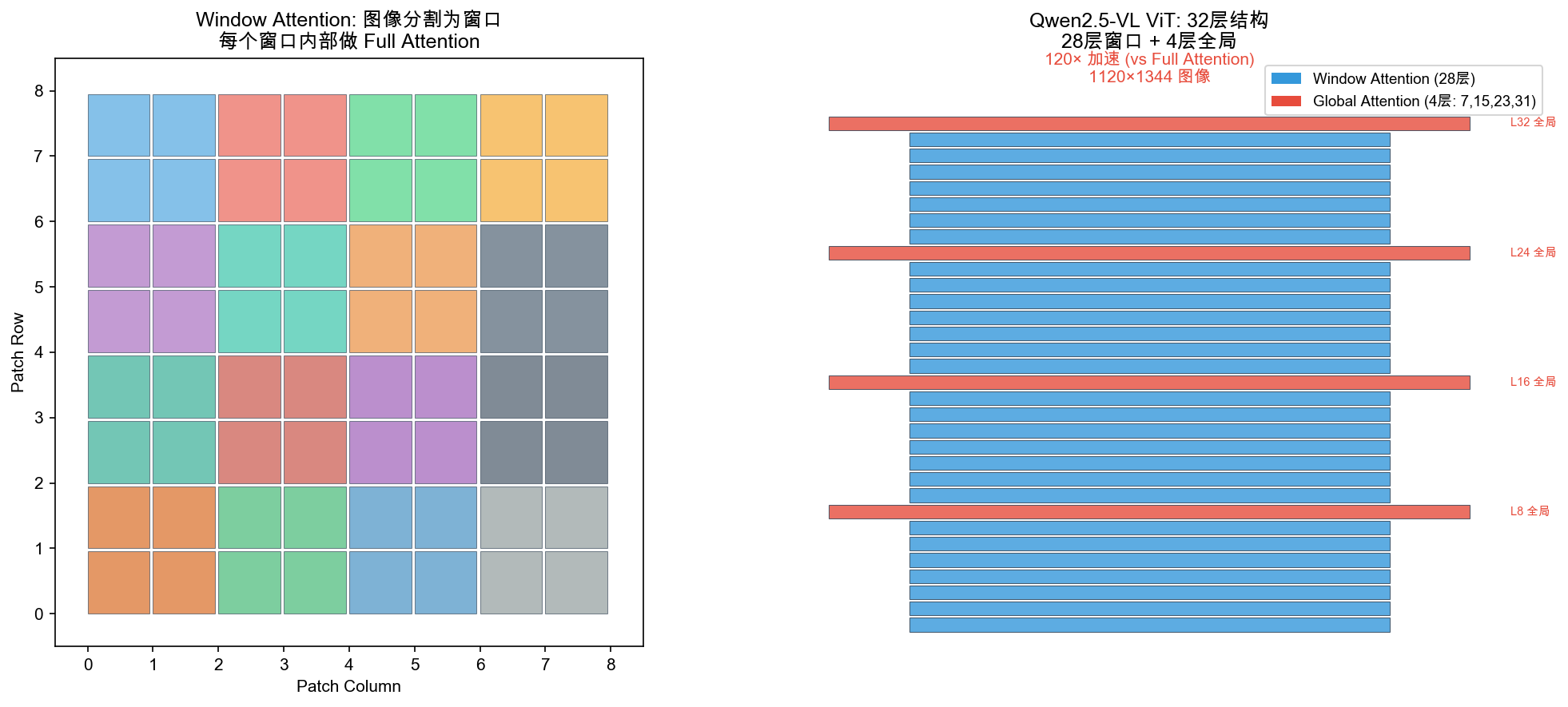
28 层 Window + 4 层 Global(第 7/15/23/31 层)
从零训练的设计自由度
- Window Attention:8×8 patch 窗口内注意力,O(N²) → O(N),120x 加速
- 4 层全局 Attention:浅/中/深层各有全局感知,打破信息孤岛
- 统一组件:RMSNorm + SwiGLU 与 LLM 对齐
- 三尺寸共享:3B/7B/72B 用同一 ViT(~600M),训练一次复用
ViT 是「眼睛」,无论配给初级工程师还是资深学者,人眼分辨率相同。
MLP Merger 精妙设计 + 绝对时间对齐
创新 2:MLP Merger(替代 PatchMerger)
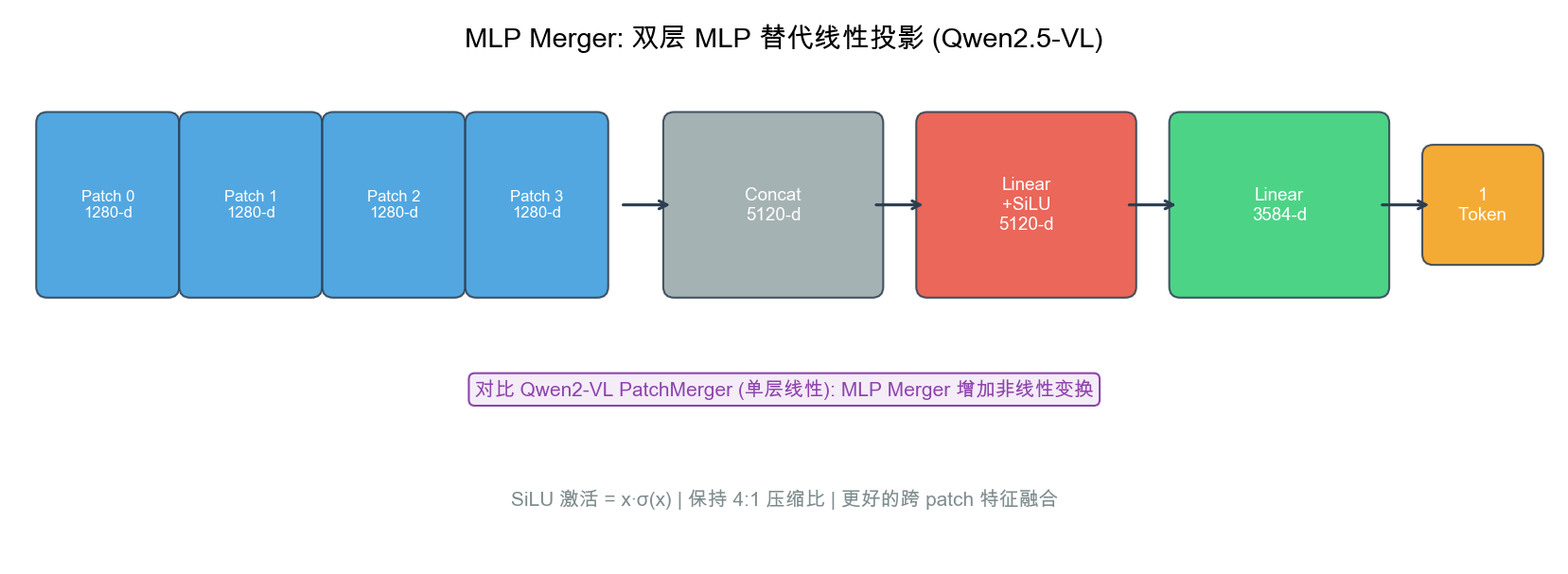
- 2×2 patch concat → 双层 MLP + SiLU → LLM hidden dim
- 非线性变换学习跨 patch 空间纹理 — 区分「一」和「二」的笔划
- 4:1 压缩,每个 LLM token 对应 28×28 像素区域
创新 3:M-RoPE 绝对时间对齐
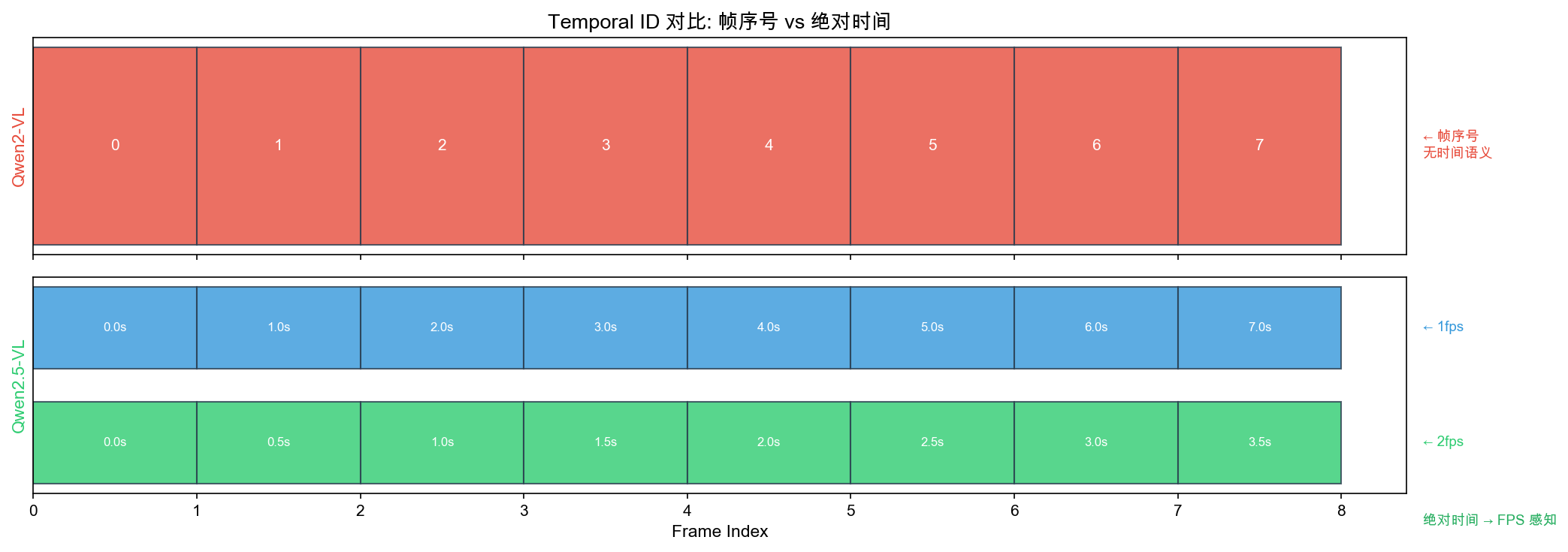
- 问题:Qwen2-VL 用帧序号(0,1,2)— 不同帧率视频无法感知真实时间
- 改进:temporal_id = 实际时间戳(秒数)
- 2fps:[0.0, 0.5, 1.0, 1.5...] / 30fps:[0.000, 0.033, 0.067...]
- Charades-STA mIoU 提升到 50.9
Qwen3-VL 创新 1:Interleaved-MRoPE 全局坐标系
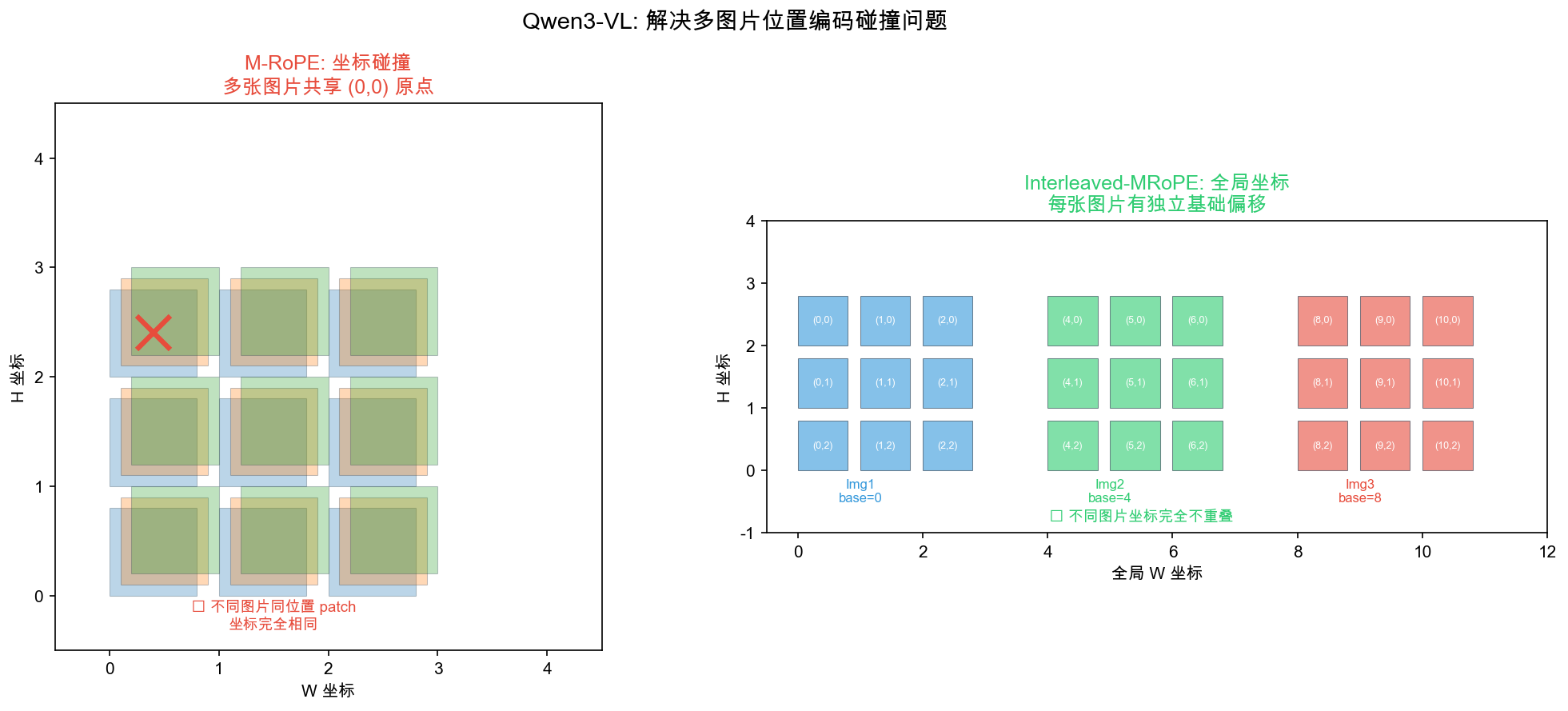
左:M-RoPE 多图坐标碰撞 / 右:全局坐标系解决方案
全局坐标系
- 每张图在全局位置空间分配唯一偏移
- h_id = base + r,w_id = base + c(base = 全局起始位置)
- 256K 上下文 100+ 张图,每个 patch 全局唯一
比喻:M-RoPE 像每栋楼都有「101 室」但不知在哪条街 — Interleaved 加了街道地址
DeepStack 多层融合 + VL 首次引入 MoE
创新 2:DeepStack 多层 ViT 特征融合
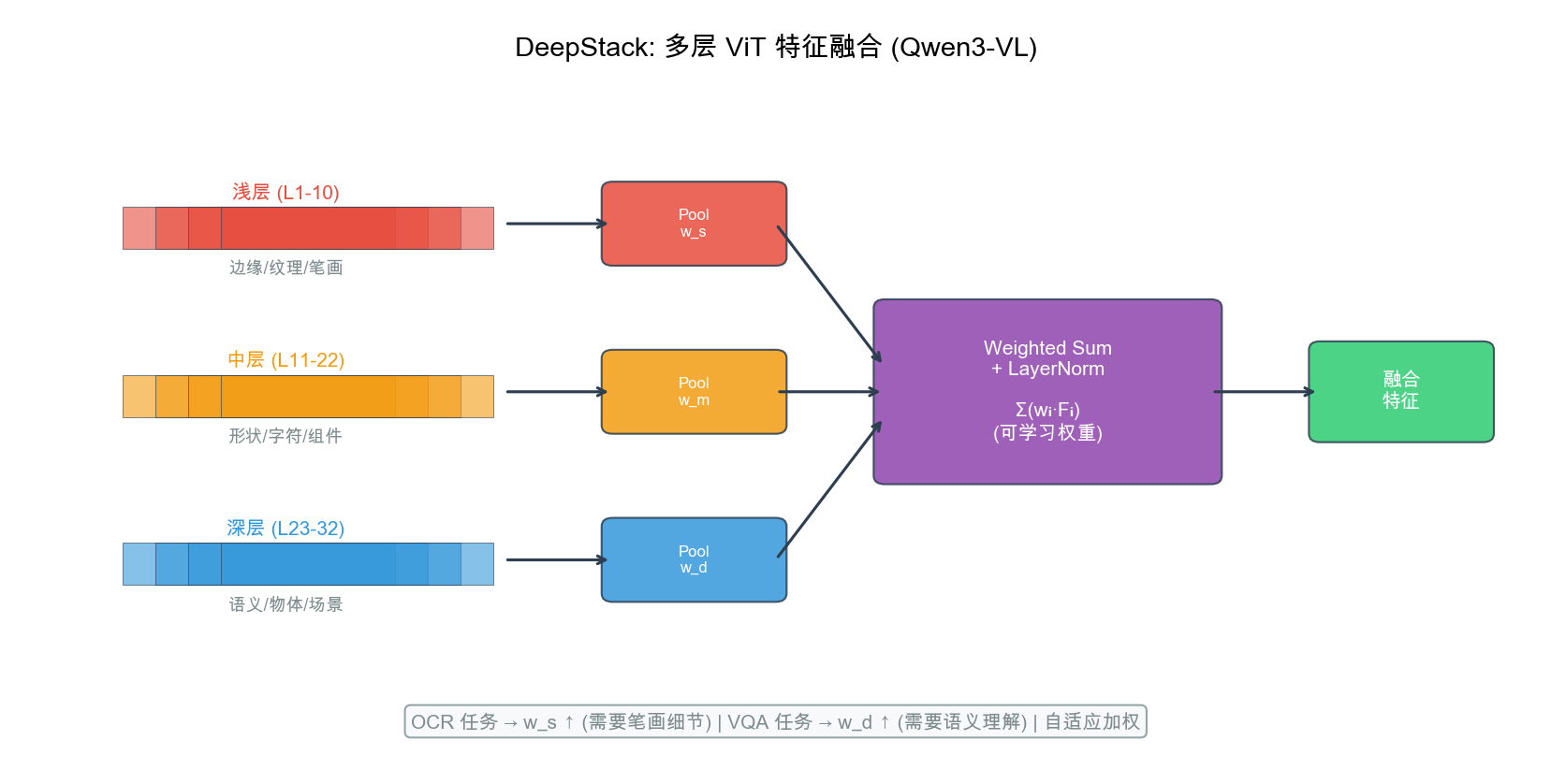
- Qwen2.5-VL 仅用 ViT 最后一层 — 深层语义丰富但浅层细节丢失
- 浅层(1-10):边缘/笔划 → OCR
- 中层(11-22):字符组合 → 文字行
- 深层(23-32):全局语义 → VQA
- 可学习权重自适应融合,OCR 加大浅层,VQA 加大深层
创新 3:MoE 首入 VL 领域
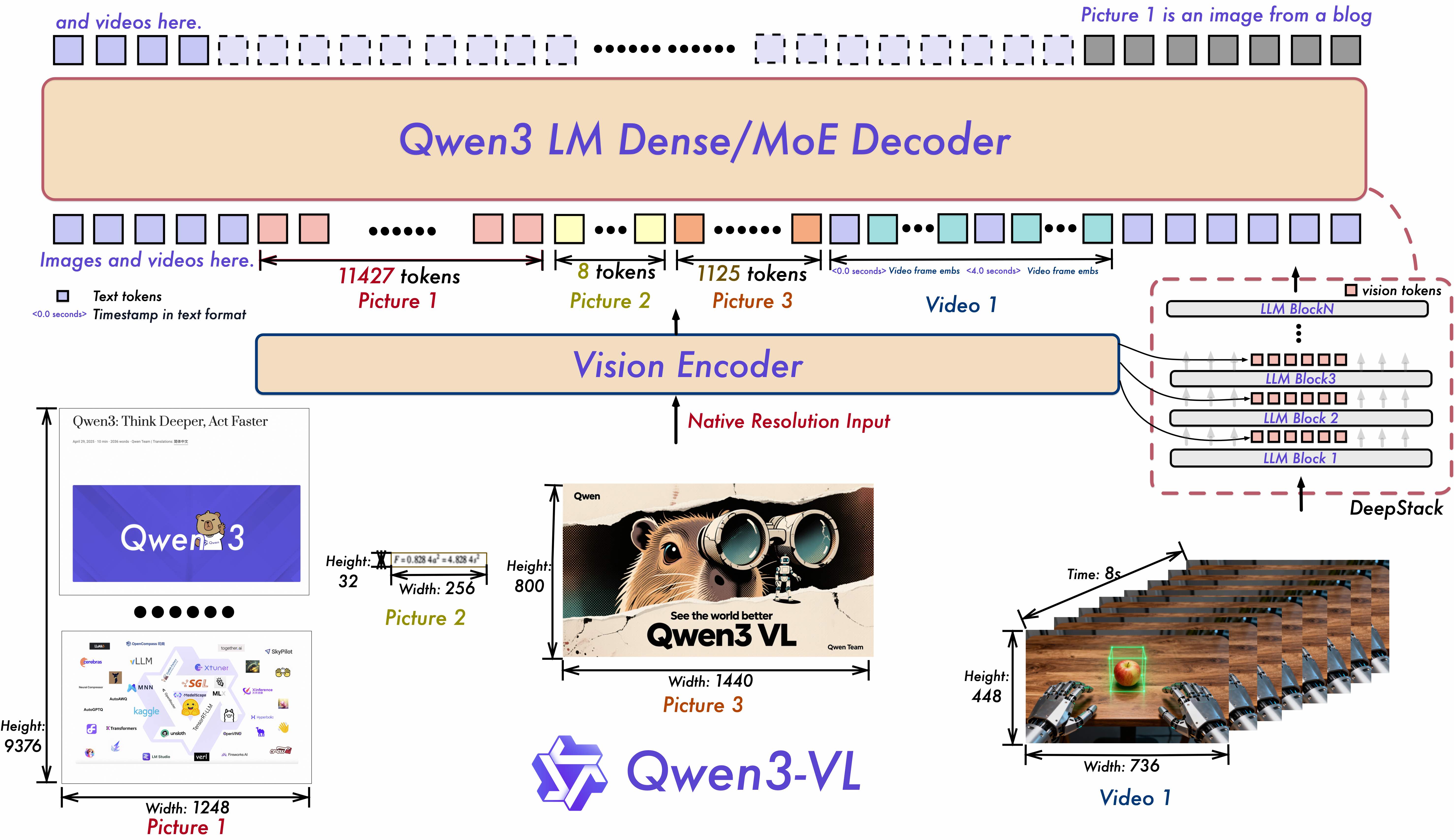
- Qwen3-VL-235B-A22B:128 专家 + 8 激活 + 1 共享
- VL 任务多样性(OCR/VQA/Grounding/视频/GUI)→ 不同专家子集
- Thinking Mode:视觉 CoT + GRPO 强化学习
- 256K 原生多模态上下文:100+ 图 / 60+ 分钟视频
Qwen2.5-Omni 创新 1:Thinker-Talker 双轨架构
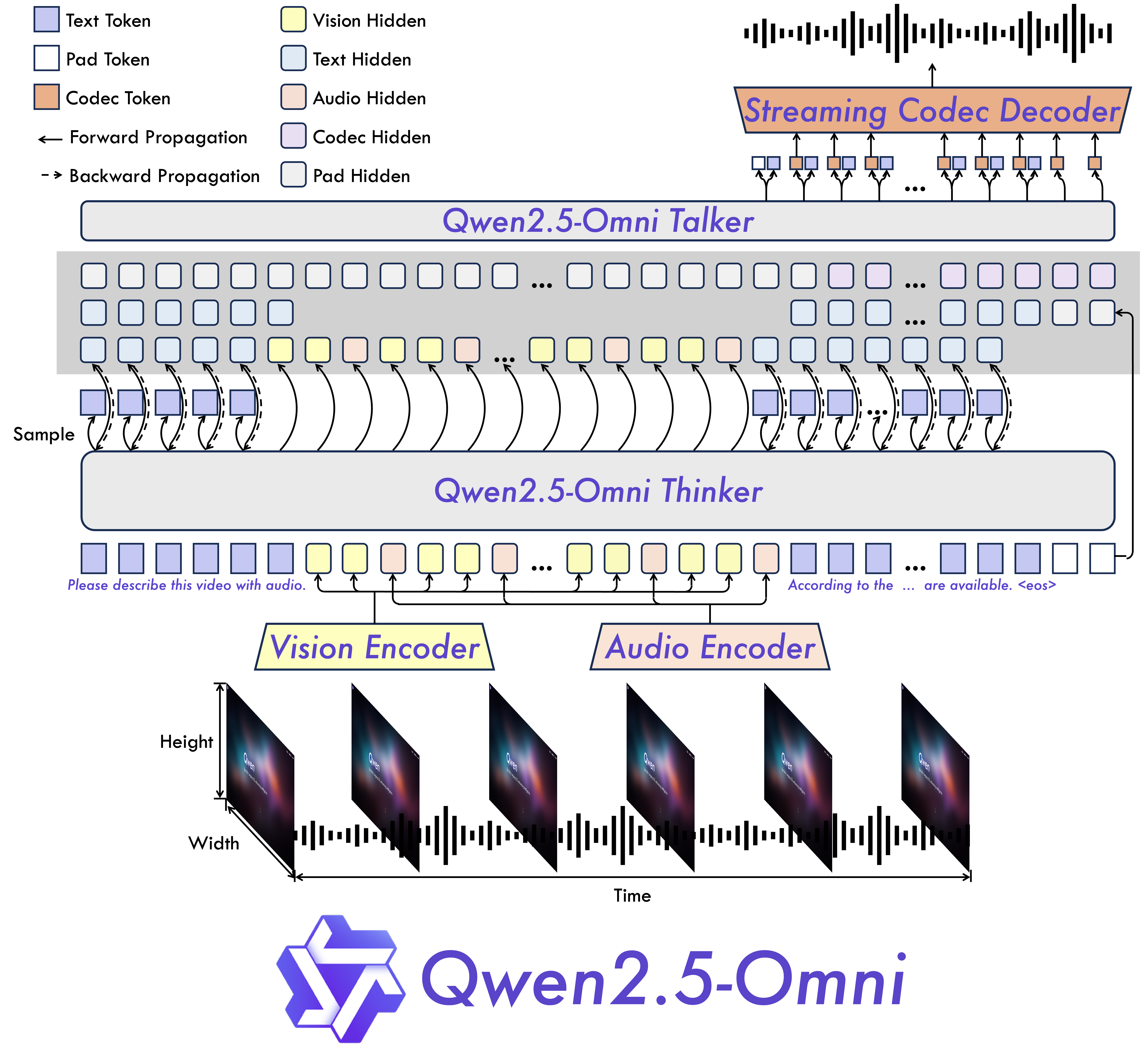
Thinker(推理大脑)+ Talker(语音嘴巴)
Thinker:多模态感知大脑
- Qwen2.5-7B 骨干,输入文本+图像+音频+视频
- 输出 ①文本 token ②Hidden States(传给 Talker)
Talker:语音合成嘴巴
- 轻量 Transformer,接收 Hidden States + 历史 audio codec
- 与 Thinker 并行运行,边理解边说
TMRoPE 物理时间轴 + 流式音频编码
创新 2:TMRoPE — 统一物理时间坐标
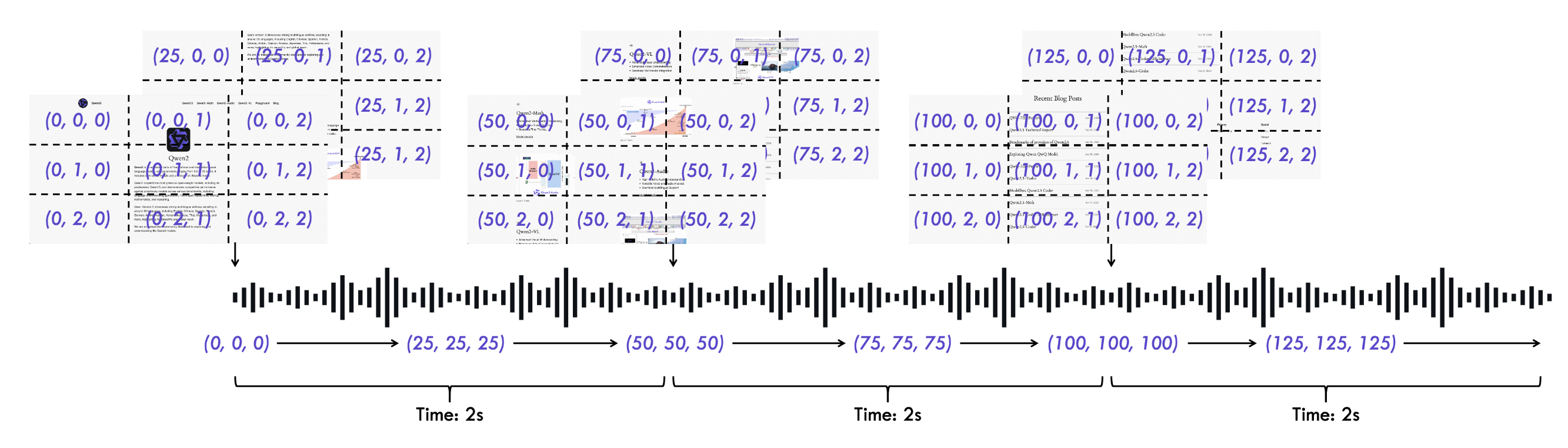
- 问题:视频帧和音频块时间单位不统一
- 方案:pos_idt = ⌊实际秒数 × rref⌋
- 同一时刻的音视频 token 自动获得相近 temporal ID
- 模型隐式学习「画面嘴动 ↔ 声音出现」的时序关联
创新 3:Whisper-like 流式音频编码
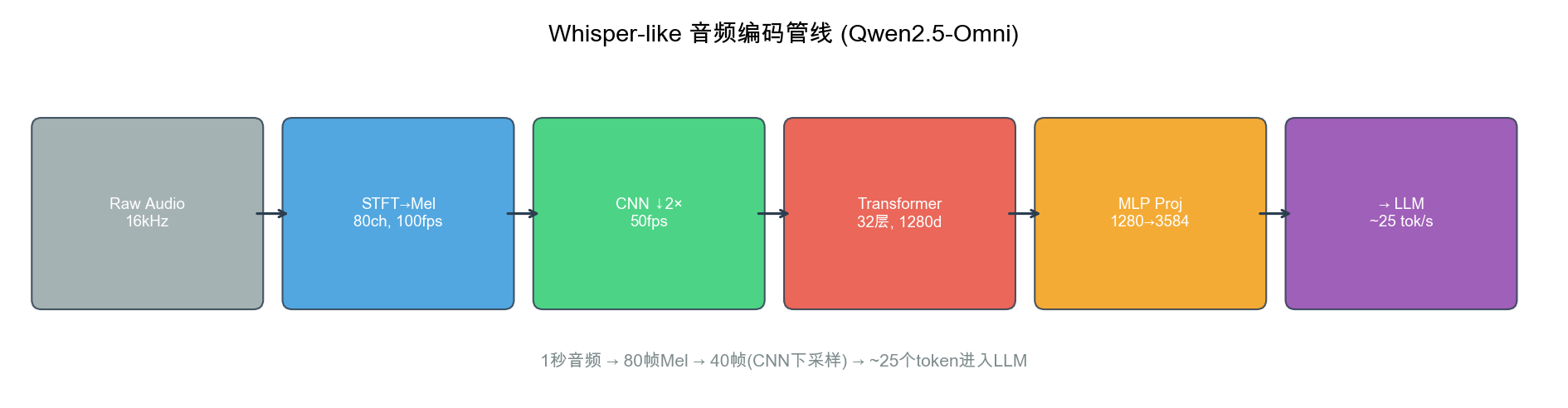
- 16kHz → 80ch Mel → CNN 2x 下采样 → Transformer 32 层 → MLP
- Block-wise 流式:每 ~2 秒一个 Block,边接收边理解
- 首包延迟 = 1 个 Block 处理时间,而非完整说话时长
Qwen3-Omni 创新 1:DiT → Causal ConvNet
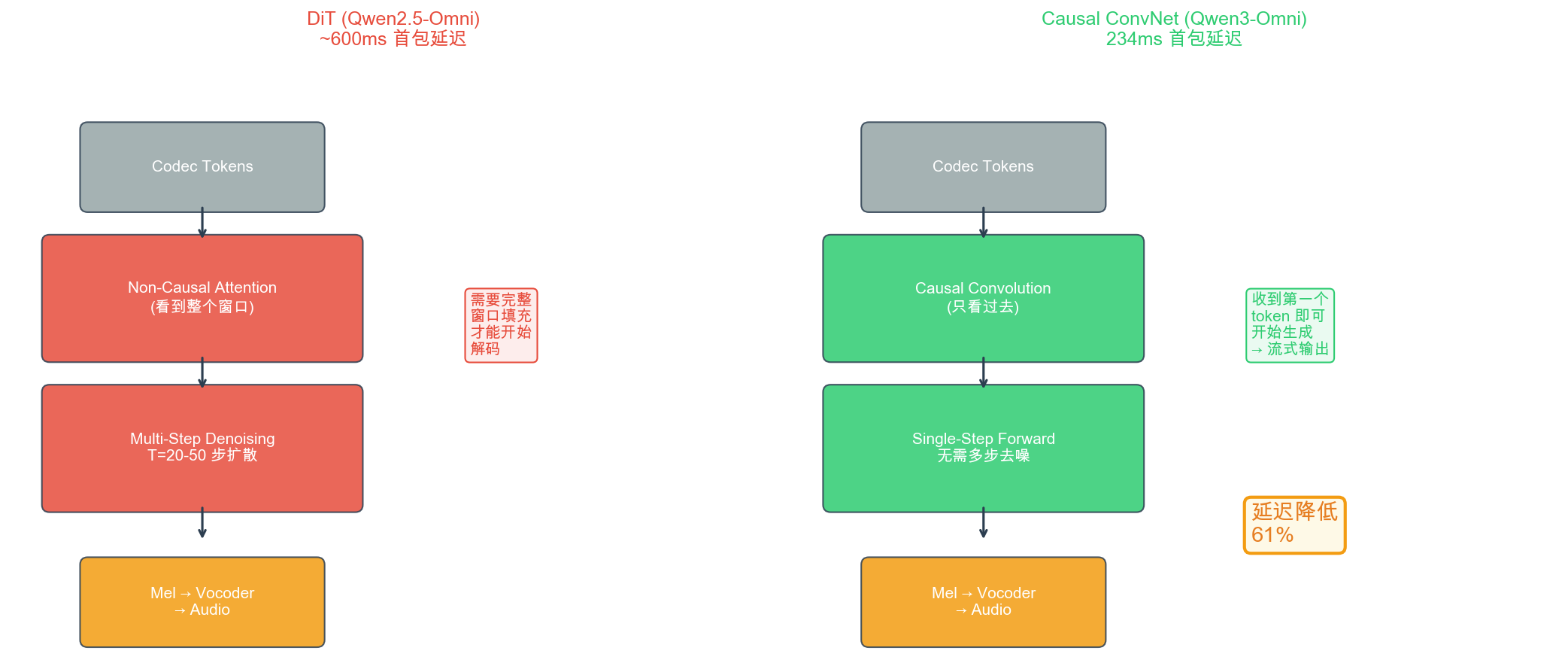
DiT(非因果多步 ~600ms)→ Causal ConvNet(因果单步 234ms)
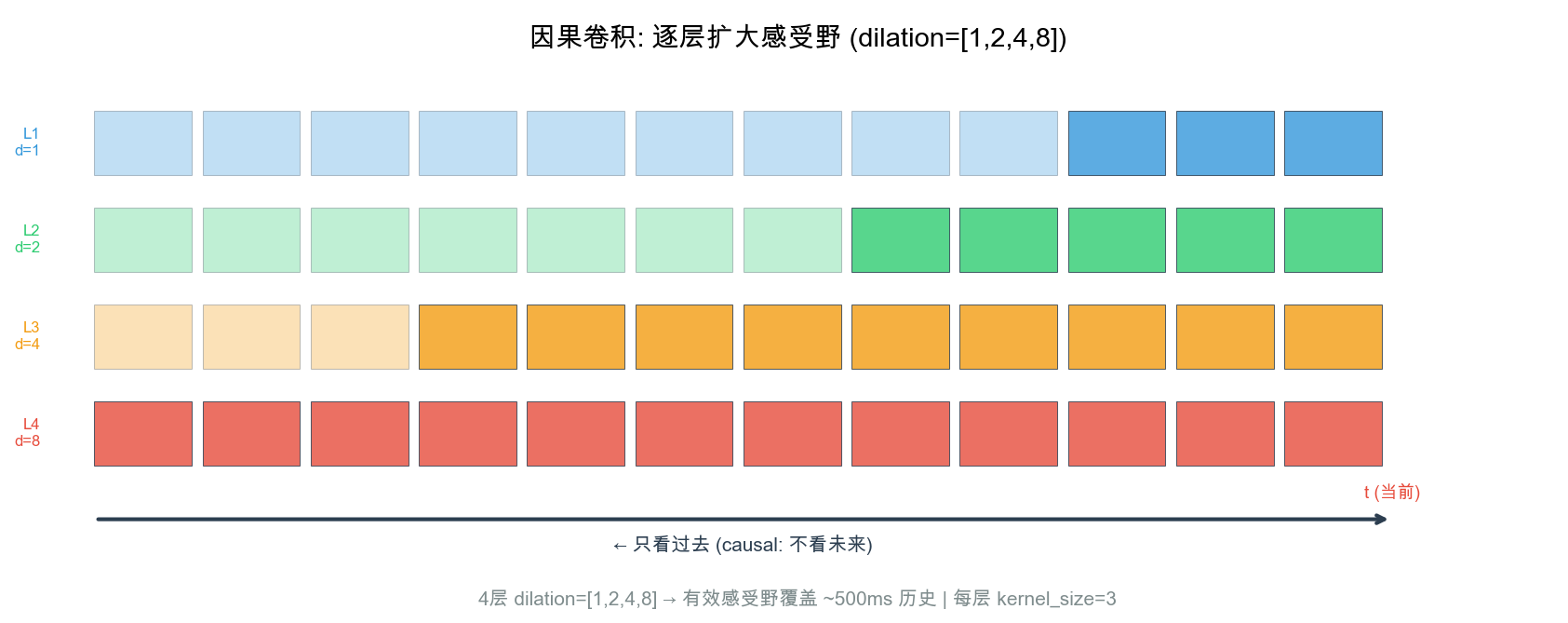
膨胀因果卷积:dilation=1,2,4,8 扩展感受野
DiT 的两个延迟瓶颈
- 非因果感受野:等待窗口填满 ~500ms
- 多步迭代去噪:20-50 步扩散 ~100-300ms
Causal ConvNet 方案
- 严格因果:padding 只在左侧,不看未来
- 单步前向:O(1) 延迟 vs DiT 的 O(W)+O(T)
- 膨胀卷积:4 层覆盖 ~500ms 历史上下文
- + Multi-Codebook RVQ 补偿声学细节
234ms 首包延迟 + Multi-Codebook RVQ
创新 2:延迟分解 — 234ms 瀑布图
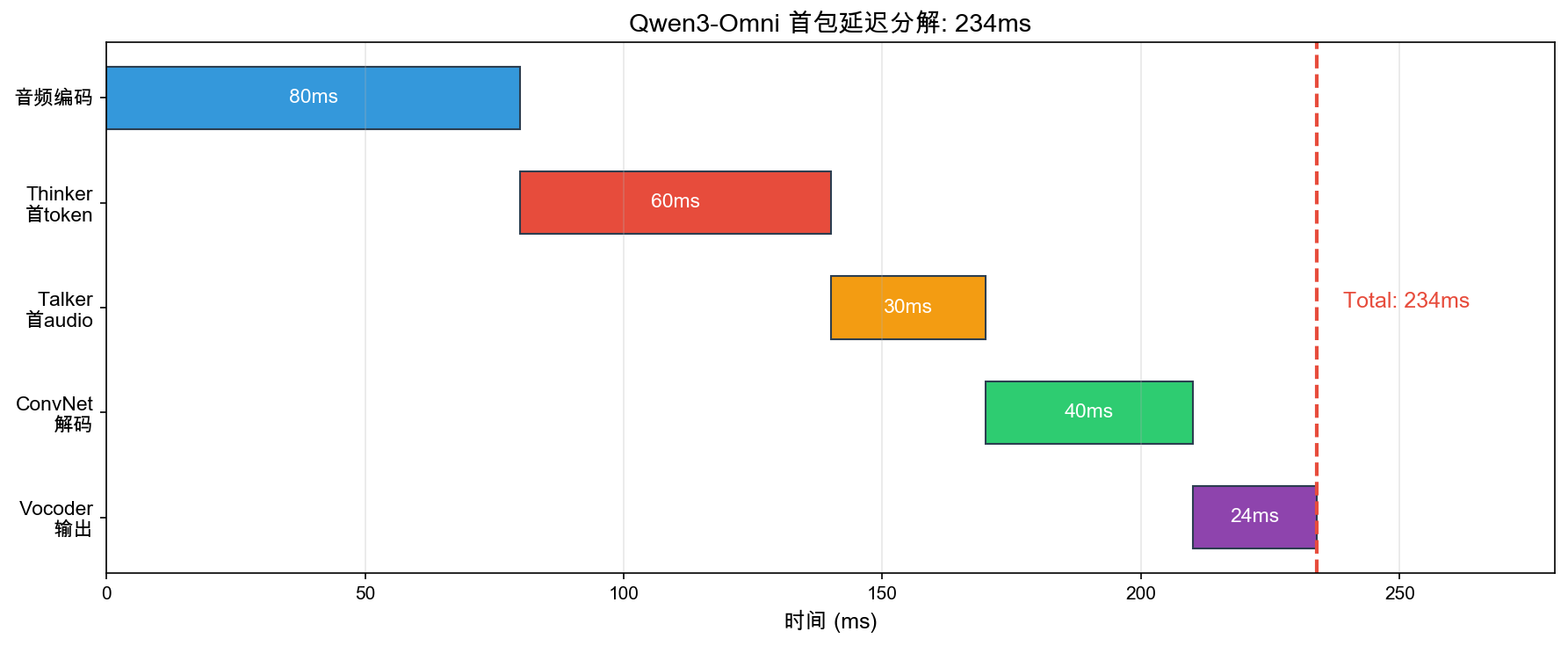
| 环节 | 耗时 |
|---|---|
| 音频编码(first block) | ~80ms |
| Thinker 首 token | ~60ms |
| Talker 首 audio token | ~30ms |
| ConvNet 解码(单步) | ~40ms |
| Vocoder 首帧 | ~24ms |
| 总计 | 234ms |
创新 3:Multi-Codebook RVQ
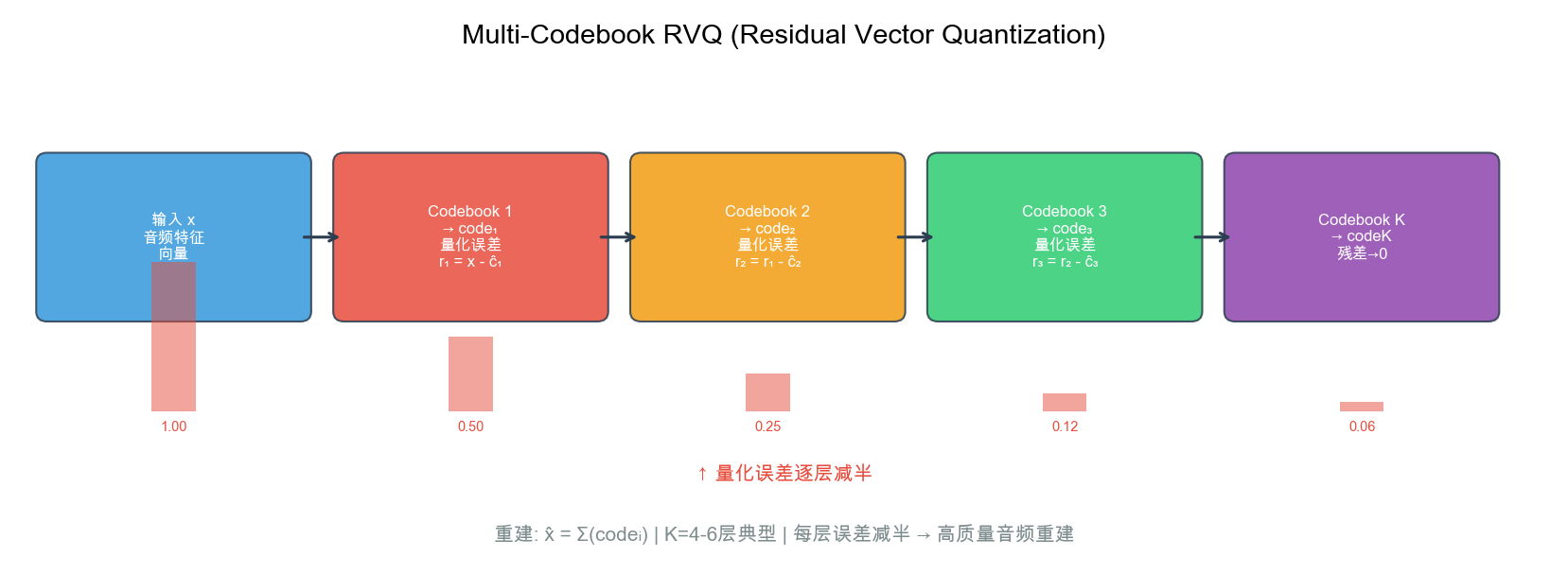
- 多层码本逐层量化残差:每增一层,误差减半
- K 层后误差 ≈ 原始的 2-K
- 为 Causal ConvNet 提供更丰富输入:单层→多层 codes
- 最终音质差距缩小到 <5% MOS
VL 模型四代核心演进对比
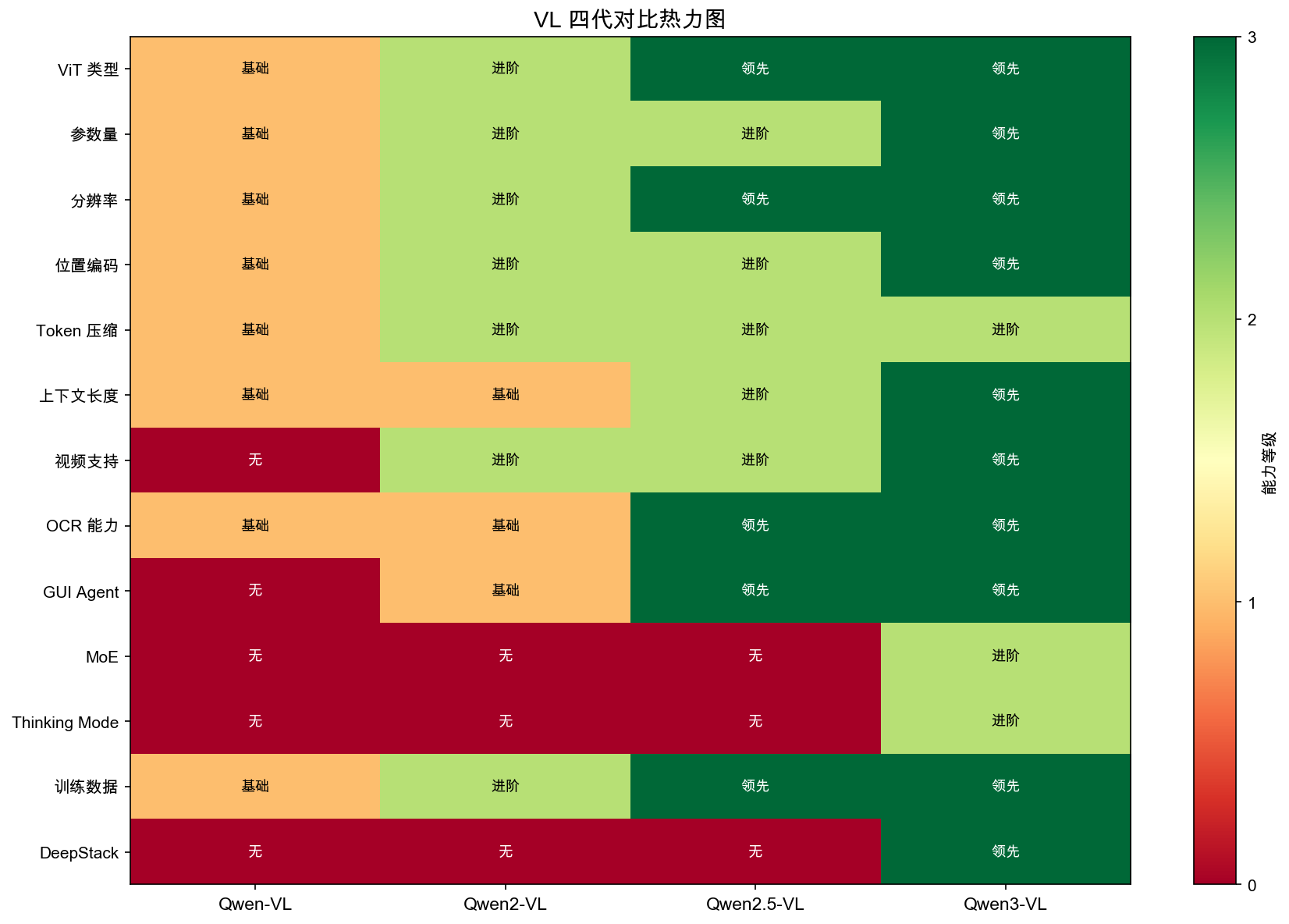
| 维度 | Qwen-VL | Qwen2-VL | Qwen2.5-VL | Qwen3-VL |
|---|---|---|---|---|
| 视觉编码器 | CLIP ViT 固定 | DFN ViT 675M | 从零训练+Window | +DeepStack |
| 融合机制 | Cross-Attention | PatchMerger | MLP Merger | +多层融合 |
| 位置编码 | 2D 绝对 | M-RoPE | M-RoPE+绝对时间 | Interleaved-MRoPE |
| MoE / Thinking | ❌ / ❌ | ❌ / ❌ | ❌ / ❌ | ✅ / ✅ |
| 上下文 | 2-8K | 32-128K | 128K | 256K |
纯文本 vs VL vs Omni 管线对比
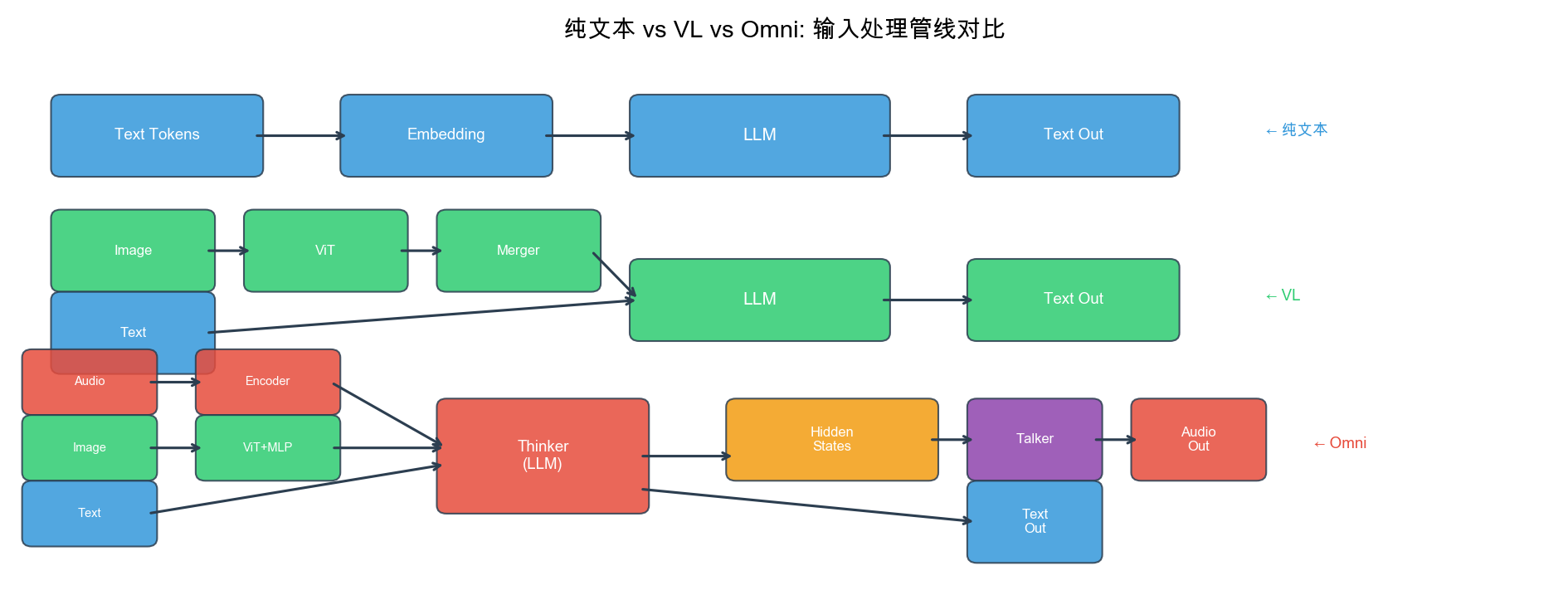
| 维度 | 纯文本 LLM | VL 模型 | Omni 模型 |
|---|---|---|---|
| 输入模态 | 文本 | 文本 + 图像/视频 | 文本 + 图像/视频 + 音频 |
| 输出模态 | 文本 | 文本(含坐标) | 文本 + 流式语音 |
| 生成架构 | 单路自回归 | 单路自回归 | Thinker + Talker 双轨并行 |
| 位置编码 | 1D-RoPE | M-RoPE / Interleaved | TMRoPE(物理时间轴) |
| KV cache 压力 | 中 | 高(大量视觉 token) | 极高(实时递增音频) |